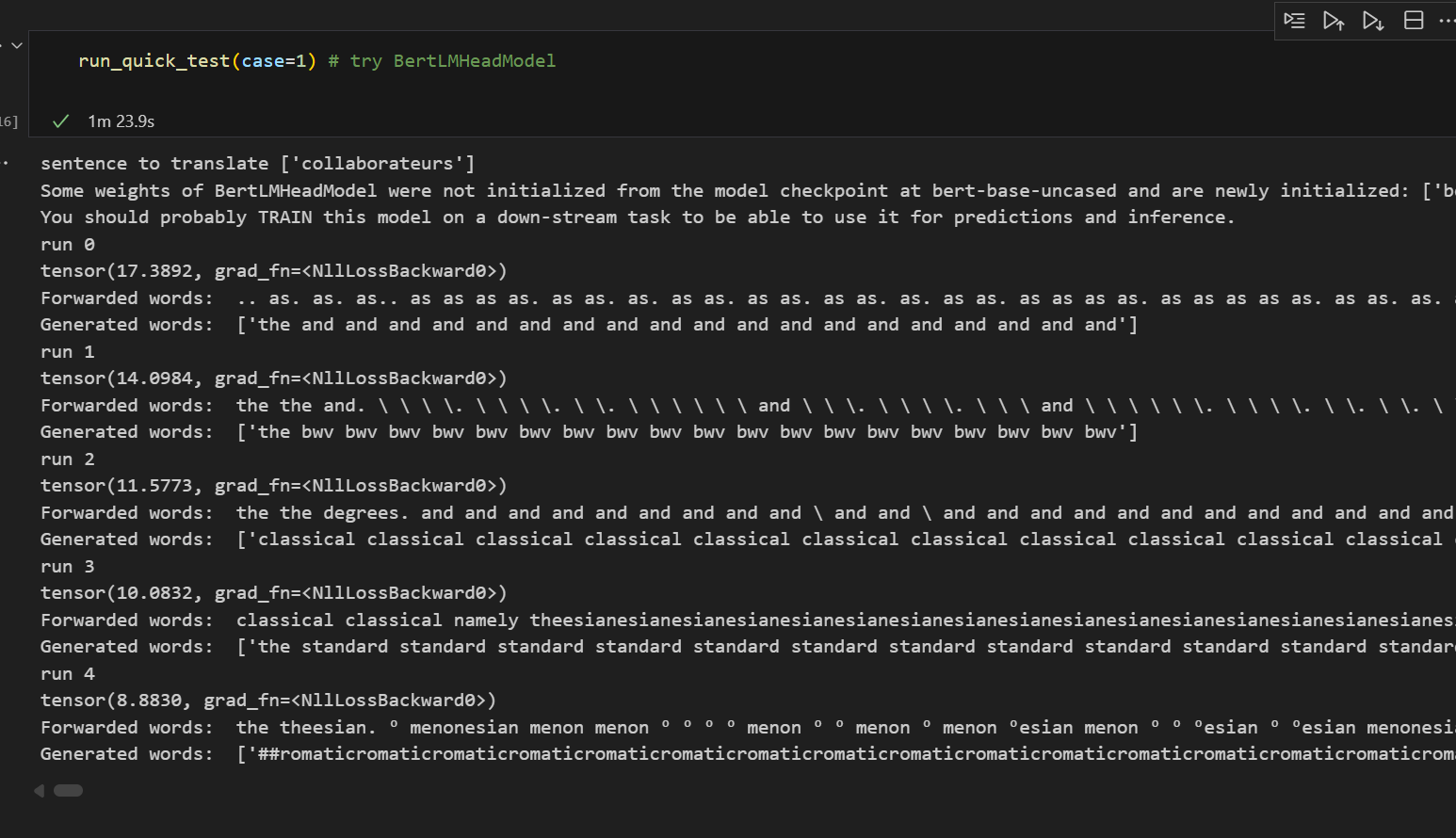
The above solution is just to suppress PAD tokens…
When actually implementing this, you will need to perform actual training and use a tokenizer that supports both languages.
# pip install -U transformers datasets
import random, math
import torch
from torch.utils.data import DataLoader
from torch.optim import AdamW
from datasets import load_dataset
from transformers import (
AutoTokenizer, AutoModel, BertConfig, BertLMHeadModel, EncoderDecoderModel
)
# ---- config
SEED = 0
SRC_CKPT = "bert-base-uncased" # encoder (EN)
TGT_CKPT = "bert-base-multilingual-cased" # decoder (FR-capable)
MAX_SRC_LEN = 96
MAX_TGT_LEN = 96
BATCH_SIZE = 8
EPOCHS = 10 # raise to 20–30 if not overfitting
LR = 5e-5
random.seed(SEED)
torch.manual_seed(SEED)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# ---- tokenizers
tok_src = AutoTokenizer.from_pretrained(SRC_CKPT)
tok_tgt = AutoTokenizer.from_pretrained(TGT_CKPT)
PAD_ID = tok_tgt.pad_token_id
EOS_ID = tok_tgt.sep_token_id
BOS_ID = tok_tgt.cls_token_id
# ---- model: BERT encoder + BERT LM-head decoder with cross-attn
dec_cfg = BertConfig.from_pretrained(TGT_CKPT, is_decoder=True, add_cross_attention=True)
model = EncoderDecoderModel(
encoder=AutoModel.from_pretrained(SRC_CKPT),
decoder=BertLMHeadModel.from_pretrained(TGT_CKPT, config=dec_cfg),
).to(device)
# required special ids for training (right-shift) and decode
model.config.decoder_start_token_id = BOS_ID
model.config.eos_token_id = EOS_ID
model.config.pad_token_id = PAD_ID
model.config.tie_encoder_decoder = False
model.config.vocab_size = model.config.decoder.vocab_size
# ---- tiny EN–FR set: take 100 pairs from OPUS Books
# notes: you can replace this with your own parallel lists
ds = load_dataset("Helsinki-NLP/opus_books", "en-fr", split="train") # ~1M pairs
pairs = [(ex["translation"]["en"], ex["translation"]["fr"]) for ex in ds.select(range(2000))]
random.shuffle(pairs)
pairs = pairs[:100] # exactly 100
src_list, tgt_list = zip(*pairs)
# ---- helpers
def build_batch(src_texts, tgt_texts):
# source
X = tok_src(
list(src_texts), padding=True, truncation=True, max_length=MAX_SRC_LEN, return_tensors="pt"
)
# target labels: NO BOS; append EOS; mask PAD with -100
Y = tok_tgt(
list(tgt_texts), padding="max_length", truncation=True, max_length=MAX_TGT_LEN,
add_special_tokens=False, return_tensors="pt"
)["input_ids"]
# append EOS before padding if room
Y_fixed = torch.full_like(Y, PAD_ID)
for i in range(Y.size(0)):
toks = [t for t in Y[i].tolist() if t != PAD_ID]
if len(toks) < MAX_TGT_LEN:
toks = toks + [EOS_ID]
toks = toks[:MAX_TGT_LEN]
Y_fixed[i, :len(toks)] = torch.tensor(toks, dtype=Y_fixed.dtype)
labels = Y_fixed.clone()
labels[labels == PAD_ID] = -100
return {k: v.to(device) for k, v in X.items()}, labels.to(device)
def collate(batch):
s, t = zip(*batch)
return build_batch(s, t)
# simple Dataset wrapper
class Pairs(torch.utils.data.Dataset):
def __init__(self, srcs, tgts):
self.s = list(srcs); self.t = list(tgts)
def __len__(self): return len(self.s)
def __getitem__(self, i): return self.s[i], self.t[i]
train_dl = DataLoader(Pairs(src_list, tgt_list), batch_size=BATCH_SIZE, shuffle=True, collate_fn=collate)
@torch.inference_mode()
def translate_samples(texts, n=5):
X = tok_src(list(texts[:n]), return_tensors="pt", padding=True, truncation=True, max_length=MAX_SRC_LEN).to(device)
out = model.generate(
X["input_ids"], attention_mask=X["attention_mask"],
num_beams=4, max_new_tokens=64, early_stopping=True,
decoder_start_token_id=BOS_ID, eos_token_id=EOS_ID, pad_token_id=PAD_ID,
bad_words_ids=[[PAD_ID]], # block PAD
repetition_penalty=1.1, # mild
no_repeat_ngram_size=3 # optional hygiene
)
return [tok_tgt.decode(o, skip_special_tokens=True) for o in out]
def show_before_after(k=5):
print("\n--- BEFORE ---")
preds_before = translate_samples(src_list, n=k)
for i in range(k):
print(f"EN: {src_list[i]}")
print(f"FR_gold: {tgt_list[i]}")
print(f"FR_pred: {preds_before[i]}")
print("-")
# train then test again
model.train()
opt = AdamW(model.parameters(), lr=LR)
steps = 0
for epoch in range(EPOCHS):
for X, labels in train_dl:
opt.zero_grad()
out = model(input_ids=X["input_ids"], attention_mask=X["attention_mask"], labels=labels)
out.loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
opt.step()
steps += 1
print(f"epoch {epoch+1}/{EPOCHS} done")
model.eval()
print("\n--- AFTER ---")
preds_after = translate_samples(src_list, n=k)
for i in range(k):
print(f"EN: {src_list[i]}")
print(f"FR_gold: {tgt_list[i]}")
print(f"FR_pred: {preds_after[i]}")
print("-")
if __name__ == "__main__":
print(f"device: {device}")
show_before_after(k=5)
"""
--- BEFORE ---
EN: As for me, I found myself obliged, the first time for months, to face alone a long Thursday evening - with the clear feeling that the old carriage had borne away my youth forever.
FR_gold: Quant à moi, je me trouvai, pour la première fois depuis de longs mois, seul en face d’une longue soirée de jeudi – avec l’impression que, dans cette vieille voiture, mon adolescence venait de s’en aller pour toujours.
FR_pred: ##iiilililiililiiliiliilingingiingiingiingingingingiiliiliingiingiiliiliigingingillingingighingiingingiingiiliingingiiliingiigiingiingieningingioviingiinginiingiingiiingiingighinginginingingiigingi
-
EN: No one asked him who Booby was.
FR_gold: Personne ne lui demanda qui était Ganache.
FR_pred: a a a - - - a a A A A a a ad ad ad Ad Ad Ad ad ad a a, a a ae ae ae a A a A,, A A, - -,,, a,,. - - an an an,, an an - - A A - - 1 -
-
EN: M. Seurel's here .. .'
FR_gold: M. Seurel est là…
FR_pred: ##ggg22233322443344423243234377799988877889979773378789786779777688
-
EN: After the ball where everything was charming but feverish and mad, where he had himself so madly chased the tall Pierrot, Meaulnes found that he had dropped into the most peaceful happiness on earth.
FR_gold: Après cette fête où tout était charmant, mais fiévreux et fou, où lui-même avait si follement poursuivi le grand pierrot, Meaulnes se trouvait là plongé dans le bonheur le plus calme du monde.
FR_pred: ##iiilililiiiiliilililiiliiliigiigiigiiliiliiliingiingiingiiliilingingingiingiingiigiigingingiigiigiingiingingingiiliigiingiigingiingiigiingingiingingiigiingiiciingiingificiingiingiiciigiigiiciingi
-
EN: At half-past eight, just as M. Seurel was giving the signal to enter school, we arrived, quite out of breath, to line up.
FR_gold: À huit heures et demie, à l’instant où M. Seurel allait donner le signal d’entrer, nous arrivâmes tout essoufflés pour nous mettre sur les rangs.
FR_pred: ##jajajajanjanjanjajajanojanjanjaljanjan sal sal saljanjan sino sino sinojanjanjanojanojanojanjano sino sinojanojano sal salcolcolcolcalcalcalcolcol sal salsal sal salallallall sal sal alcolcolsalsalcolcol - - sal sal
-
--- AFTER ---
EN: As for me, I found myself obliged, the first time for months, to face alone a long Thursday evening - with the clear feeling that the old carriage had borne away my youth forever.
FR_gold: Quant à moi, je me trouvai, pour la première fois depuis de longs mois, seul en face d’une longue soirée de jeudi – avec l’impression que, dans cette vieille voiture, mon adolescence venait de s’en aller pour toujours.
FR_pred: Quant à moi, je ne voulus pas pour la première fois de soi, seul en face d une longue longue aventure de longs mois.
-
EN: No one asked him who Booby was.
FR_gold: Personne ne lui demanda qui était Ganache.
FR_pred: Personne ne lui demanda qui demanda demanda qui lui demanda demanda qu il demanda Ganache.
-
EN: M. Seurel's here .. .'
FR_gold: M. Seurel est là…
FR_pred: M. Seurel est là
-
EN: After the ball where everything was charming but feverish and mad, where he had himself so madly chased the tall Pierrot, Meaulnes found that he had dropped into the most peaceful happiness on earth.
FR_gold: Après cette fête où tout était charmant, mais fiévreux et fou, où lui-même avait si follement poursuivi le grand pierrot, Meaulnes se trouvait là plongé dans le bonheur le plus calme du monde.
FR_pred: Dès qu on le recommença plus le grand pierrot de sa société où lui même même même avait si beau.
-
EN: At half-past eight, just as M. Seurel was giving the signal to enter school, we arrived, quite out of breath, to line up.
FR_gold: À huit heures et demie, à l’instant où M. Seurel allait donner le signal d’entrer, nous arrivâmes tout essoufflés pour nous mettre sur les rangs.
FR_pred: À huit heures et demie à peine, nous arrivâmes tout tout essoufflés sur les rangs.
-
"""