Okay.
Let see if I can explain myself better with code.
This is part of my training notebook (maybe are left some imports)
As you appreciate, I set the constraint max_length=256, so longer sentences are truncated up to this length.
# download tokenizer
tokenizer = AutoTokenizer.from_pretrained(tokenizer_name)
# tokenizer helper function
def tokenize(batch):
return tokenizer(batch['text'], padding='max_length', truncation=True, max_length=256)
# tokenize dataset
train_dataset = train_dataset.map(tokenize, batched=True)
test_dataset = test_dataset.map(tokenize, batched=True)
# set format for pytorch
# train_dataset = train_dataset.rename_column("label", "labels")
train_dataset.set_format('torch', columns=['input_ids', 'attention_mask', 'labels'])
# test_dataset = test_dataset.rename_column("label", "labels")
test_dataset.set_format('torch', columns=['input_ids', 'attention_mask', 'labels'])
import botocore
from datasets.filesystems import S3FileSystem
s3 = S3FileSystem()
# save train_dataset to s3
training_input_path = f's3://{sess.default_bucket()}/{s3_prefix}/train'
train_dataset.save_to_disk(training_input_path,fs=s3)
# save test_dataset to s3
test_input_path = f's3://{sess.default_bucket()}/{s3_prefix}/test'
test_dataset.save_to_disk(test_input_path,fs=s3)
from sagemaker.huggingface import HuggingFace
# hyperparameters, which are passed into the training job
hyperparameters={
'epochs': 3,
'train_batch_size': 32,
'model_name': checkpoint
}
huggingface_estimator = HuggingFace(entry_point='train.py',
source_dir='./scripts',
instance_type='ml.p3.2xlarge',
instance_count=1,
role=role,
transformers_version='4.6',
pytorch_version='1.7',
py_version='py36',
hyperparameters = hyperparameters)
huggingface_estimator.fit({'train': training_input_path, 'test': test_input_path})
Now we go to predict. We will use to predict a sentence longer than 512 tokens (this is longer than my max_length, but also longer than the BERT max_length)
predictor = huggingface_estimator.deploy(1,"ml.g4dn.xlarge")
long_sentence = "......" # longer than 512 tokens
sentiment_input= {
"inputs": long_sentence}
predictor.predict(sentiment_input)
This throw this error:
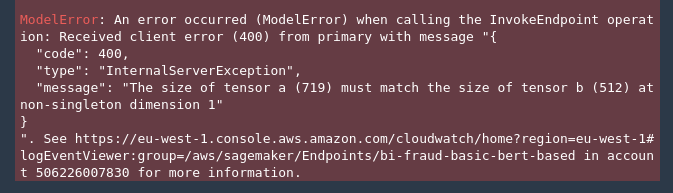
The deployment step is not using my tokenizer, since it were so, all sentences would long 256…but it isn’t. So the question is: How can I force to use my personal tokenizer at inference time?