Of course, here you go. Thank you in advance!
message
"2021-09-02 16:43:42,225 [INFO ] main com.amazonaws.ml.mms.ModelServer - "
MMS Home: /opt/conda/lib/python3.6/site-packages
Current directory: /
Temp directory: /home/model-server/tmp
Number of GPUs: 1
Number of CPUs: 8
Max heap size: 12949 M
Python executable: /opt/conda/bin/python3.6
Config file: /etc/sagemaker-mms.properties
Inference address: http://0.0.0.0:8080
Management address: http://0.0.0.0:8080
Model Store: /.sagemaker/mms/models
Initial Models: ALL
Log dir: /logs
Metrics dir: /logs
Netty threads: 0
Netty client threads: 0
Default workers per model: 1
Blacklist Regex: N/A
Maximum Response Size: 6553500
Maximum Request Size: 6553500
Preload model: false
Prefer direct buffer: false
"2021-09-02 16:43:42,323 [WARN ] W-9000-model com.amazonaws.ml.mms.wlm.WorkerLifeCycle - attachIOStreams() threadName=W-9000-model"
"2021-09-02 16:43:42,432 [INFO ] W-9000-model-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - model_service_worker started with args: --sock-type unix --sock-name /home/model-server/tmp/.mms.sock.9000 --handler sagemaker_huggingface_inference_toolkit.handler_service --model-path /.sagemaker/mms/models/model --model-name model --preload-model false --tmp-dir /home/model-server/tmp"
"2021-09-02 16:43:42,433 [INFO ] W-9000-model-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - Listening on port: /home/model-server/tmp/.mms.sock.9000"
"2021-09-02 16:43:42,434 [INFO ] W-9000-model-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - [PID] 48"
"2021-09-02 16:43:42,434 [INFO ] W-9000-model-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - MMS worker started."
"2021-09-02 16:43:42,434 [INFO ] W-9000-model-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - Python runtime: 3.6.13"
"2021-09-02 16:43:42,435 [INFO ] main com.amazonaws.ml.mms.wlm.ModelManager - Model model loaded."
"2021-09-02 16:43:42,442 [INFO ] main com.amazonaws.ml.mms.ModelServer - Initialize Inference server with: EpollServerSocketChannel."
"2021-09-02 16:43:42,453 [INFO ] W-9000-model com.amazonaws.ml.mms.wlm.WorkerThread - Connecting to: /home/model-server/tmp/.mms.sock.9000"
"2021-09-02 16:43:42,525 [INFO ] main com.amazonaws.ml.mms.ModelServer - Inference API bind to: http://0.0.0.0:8080"
"2021-09-02 16:43:42,526 [INFO ] W-9000-model-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - Connection accepted: /home/model-server/tmp/.mms.sock.9000."
Model server started.
"2021-09-02 16:43:42,530 [WARN ] pool-2-thread-1 com.amazonaws.ml.mms.metrics.MetricCollector - worker pid is not available yet."
"2021-09-02 16:43:43,658 [INFO ] pool-1-thread-3 ACCESS_LOG - /169.254.255.130:42100 ""GET /ping HTTP/1.1"" 200 16"
"2021-09-02 16:43:43,670 [INFO ] epollEventLoopGroup-3-2 ACCESS_LOG - /169.254.255.130:42112 ""GET /execution-parameters HTTP/1.1"" 404 1"
"2021-09-02 16:43:47,797 [INFO ] W-9000-model-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - Model model loaded io_fd=0242a9fffefeff83-00000019-00000001-b754649245650bfe-427692ab"
"2021-09-02 16:43:47,799 [INFO ] W-9000-model com.amazonaws.ml.mms.wlm.WorkerThread - Backend response time: 5210"
"2021-09-02 16:43:47,801 [WARN ] W-9000-model com.amazonaws.ml.mms.wlm.WorkerLifeCycle - attachIOStreams() threadName=W-model-1"
"2021-09-02 16:43:48,242 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - Preprocess time - 0.1277923583984375 ms"
"2021-09-02 16:43:48,242 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - Predict time - 1630601028241.526 ms"
"2021-09-02 16:43:48,243 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - Postprocess time - 0.20599365234375 ms"
"2021-09-02 16:43:48,243 [INFO ] W-9000-model com.amazonaws.ml.mms.wlm.WorkerThread - Backend response time: 440"
"2021-09-02 16:43:48,243 [INFO ] W-9000-model ACCESS_LOG - /169.254.255.130:42116 ""POST /invocations HTTP/1.1"" 200 4525"
"2021-09-02 16:43:48,309 [WARN ] W-model-1-stderr com.amazonaws.ml.mms.wlm.WorkerLifeCycle - Token indices sequence length is longer than the specified maximum sequence length for this model (520 > 512). Running this sequence through the model will result in indexing errors"
"2021-09-02 16:43:48,318 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - Prediction error"
"2021-09-02 16:43:48,318 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - Traceback (most recent call last):"
"2021-09-02 16:43:48,318 [INFO ] W-9000-model com.amazonaws.ml.mms.wlm.WorkerThread - Backend response time: 11"
"2021-09-02 16:43:48,318 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - File ""/opt/conda/lib/python3.6/site-packages/sagemaker_huggingface_inference_toolkit/handler_service.py"", line 222, in handle"
"2021-09-02 16:43:48,318 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - response = self.transform_fn(self.model, input_data, content_type, accept)"
"2021-09-02 16:43:48,318 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - File ""/opt/conda/lib/python3.6/site-packages/sagemaker_huggingface_inference_toolkit/handler_service.py"", line 181, in transform_fn"
"2021-09-02 16:43:48,319 [INFO ] W-9000-model ACCESS_LOG - /169.254.255.130:42116 ""POST /invocations HTTP/1.1"" 400 13"
"2021-09-02 16:43:48,319 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - predictions = self.predict(processed_data, model)"
"2021-09-02 16:43:48,319 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - File ""/opt/conda/lib/python3.6/site-packages/sagemaker_huggingface_inference_toolkit/handler_service.py"", line 147, in predict"
"2021-09-02 16:43:48,319 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - prediction = model(inputs, **parameters)"
"2021-09-02 16:43:48,319 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - File ""/opt/conda/lib/python3.6/site-packages/transformers/pipelines/text_classification.py"", line 65, in __call__"
"2021-09-02 16:43:48,319 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - outputs = super().__call__(*args, **kwargs)"
"2021-09-02 16:43:48,320 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - File ""/opt/conda/lib/python3.6/site-packages/transformers/pipelines/base.py"", line 676, in __call__"
"2021-09-02 16:43:48,320 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - return self._forward(inputs)"
"2021-09-02 16:43:48,320 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - File ""/opt/conda/lib/python3.6/site-packages/transformers/pipelines/base.py"", line 697, in _forward"
"2021-09-02 16:43:48,320 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - predictions = self.model(**inputs)[0].cpu()"
"2021-09-02 16:43:48,320 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - File ""/opt/conda/lib/python3.6/site-packages/torch/nn/modules/module.py"", line 727, in _call_impl"
"2021-09-02 16:43:48,320 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - result = self.forward(*input, **kwargs)"
"2021-09-02 16:43:48,320 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - File ""/opt/conda/lib/python3.6/site-packages/transformers/models/bert/modeling_bert.py"", line 1511, in forward"
"2021-09-02 16:43:48,321 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - return_dict=return_dict,"
"2021-09-02 16:43:48,321 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - File ""/opt/conda/lib/python3.6/site-packages/torch/nn/modules/module.py"", line 727, in _call_impl"
"2021-09-02 16:43:48,321 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - result = self.forward(*input, **kwargs)"
"2021-09-02 16:43:48,321 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - File ""/opt/conda/lib/python3.6/site-packages/transformers/models/bert/modeling_bert.py"", line 969, in forward"
"2021-09-02 16:43:48,322 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - past_key_values_length=past_key_values_length,"
"2021-09-02 16:43:48,322 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - File ""/opt/conda/lib/python3.6/site-packages/torch/nn/modules/module.py"", line 727, in _call_impl"
"2021-09-02 16:43:48,322 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - result = self.forward(*input, **kwargs)"
"2021-09-02 16:43:48,322 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - File ""/opt/conda/lib/python3.6/site-packages/transformers/models/bert/modeling_bert.py"", line 207, in forward"
"2021-09-02 16:43:48,322 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - embeddings += position_embeddings"
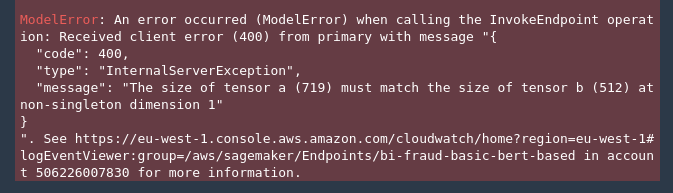
"2021-09-02 16:43:48,323 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - RuntimeError: The size of tensor a (520) must match the size of tensor b (512) at non-singleton dimension 1"
"2021-09-02 16:43:48,323 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - "
"2021-09-02 16:43:48,323 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - During handling of the above exception, another exception occurred:"
"2021-09-02 16:43:48,323 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - "
"2021-09-02 16:43:48,323 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - Traceback (most recent call last):"
"2021-09-02 16:43:48,323 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - File ""/opt/conda/lib/python3.6/site-packages/mms/service.py"", line 108, in predict"
"2021-09-02 16:43:48,324 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - ret = self._entry_point(input_batch, self.context)"
"2021-09-02 16:43:48,324 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - File ""/opt/conda/lib/python3.6/site-packages/sagemaker_huggingface_inference_toolkit/handler_service.py"", line 231, in handle"
"2021-09-02 16:43:48,324 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - raise PredictionException(str(e), 400)"
"2021-09-02 16:43:48,324 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - mms.service.PredictionException: The size of tensor a (520) must match the size of tensor b (512) at non-singleton dimension 1 : 400"
"2021-09-02 16:43:48,337 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - Prediction error"
"2021-09-02 16:43:48,337 [INFO ] W-9000-model com.amazonaws.ml.mms.wlm.WorkerThread - Backend response time: 1"
"2021-09-02 16:43:48,337 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - Traceback (most recent call last):"
"2021-09-02 16:43:48,338 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - File ""/opt/conda/lib/python3.6/site-packages/sagemaker_huggingface_inference_toolkit/handler_service.py"", line 222, in handle"
"2021-09-02 16:43:48,338 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - response = self.transform_fn(self.model, input_data, content_type, accept)"
"2021-09-02 16:43:48,338 [INFO ] W-9000-model ACCESS_LOG - /169.254.255.130:42142 ""POST /invocations HTTP/1.1"" 400 3"
"2021-09-02 16:43:48,338 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - File ""/opt/conda/lib/python3.6/site-packages/sagemaker_huggingface_inference_toolkit/handler_service.py"", line 179, in transform_fn"
"2021-09-02 16:43:48,338 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - processed_data = self.preprocess(input_data, content_type)"
"2021-09-02 16:43:48,338 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - File ""/opt/conda/lib/python3.6/site-packages/sagemaker_huggingface_inference_toolkit/handler_service.py"", line 127, in preprocess"
"2021-09-02 16:43:48,339 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - decoded_input_data = decoder_encoder.decode(input_data, content_type)"
"2021-09-02 16:43:48,339 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - File ""/opt/conda/lib/python3.6/site-packages/sagemaker_huggingface_inference_toolkit/decoder_encoder.py"", line 89, in decode"
"2021-09-02 16:43:48,339 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - return decoder(content)"
"2021-09-02 16:43:48,339 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - File ""/opt/conda/lib/python3.6/site-packages/sagemaker_huggingface_inference_toolkit/decoder_encoder.py"", line 34, in decode_json"
"2021-09-02 16:43:48,339 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - return json.loads(content)"
"2021-09-02 16:43:48,340 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - File ""/opt/conda/lib/python3.6/json/__init__.py"", line 354, in loads"
"2021-09-02 16:43:48,340 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - return _default_decoder.decode(s)"
"2021-09-02 16:43:48,340 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - File ""/opt/conda/lib/python3.6/json/decoder.py"", line 342, in decode"
"2021-09-02 16:43:48,340 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - raise JSONDecodeError(""Extra data"", s, end)"
"2021-09-02 16:43:48,340 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - json.decoder.JSONDecodeError: Extra data: line 1 column 50 (char 49)"
"2021-09-02 16:43:48,341 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - "
"2021-09-02 16:43:48,342 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - During handling of the above exception, another exception occurred:"
"2021-09-02 16:43:48,342 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - "
"2021-09-02 16:43:48,342 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - Traceback (most recent call last):"
"2021-09-02 16:43:48,342 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - File ""/opt/conda/lib/python3.6/site-packages/mms/service.py"", line 108, in predict"
"2021-09-02 16:43:48,342 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - ret = self._entry_point(input_batch, self.context)"
"2021-09-02 16:43:48,342 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - File ""/opt/conda/lib/python3.6/site-packages/sagemaker_huggingface_inference_toolkit/handler_service.py"", line 231, in handle"
"2021-09-02 16:43:48,342 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - raise PredictionException(str(e), 400)"
"2021-09-02 16:43:48,342 [INFO ] W-model-1-stdout com.amazonaws.ml.mms.wlm.WorkerLifeCycle - mms.service.PredictionException: Extra data: line 1 column 50 (char 49) : 400"

 .
.