### System Info
pytorch 1.11.0
py 3.8
cuda 11.3
transformers 4.26.1
data…sets 2.9.0
### Who can help?
@sgugger
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
import os
import time
import datetime
import sys
import numpy as np
import random
import torch
from torch.utils.data import Dataset, DataLoader, random_split, RandomSampler, SequentialSampler,DistributedSampler,BatchSampler
torch.manual_seed(42)
from transformers import GPT2LMHeadModel, GPT2Tokenizer, GPT2Config, GPT2Model,DataCollatorForLanguageModeling,AutoModelForCausalLM
from transformers import AdamW, get_linear_schedule_with_warmup
hf_model_path ='./Wenzhong-GPT2-110M'
tokenizer = GPT2Tokenizer.from_pretrained(hf_model_path)
tokenizer.add_special_tokens({'pad_token': '<|pad|>'})
from datasets import load_dataset
gpus=8
max_len = 576
batch_size_node = 17
save_step = 5000
gradient_accumulation = 2
dataloader_num = 4
max_step = 351000*1000//batch_size_node//gradient_accumulation//gpus
#max_step = -1
print("total_step:%d"%(max_step))
import datasets
datasets.__version__
dataset = load_dataset("text", data_files="./gpt_data_v1/*",split='train',cache_dir='./dataset_cache',streaming=True)
print('load over')
shuffled_dataset = dataset.shuffle(seed=42)
print('shuffle over')
def dataset_tokener(example,max_lenth=max_len):
example['text'] = list(map(lambda x : x.strip()+'<|endoftext|>',example['text'] ))
return tokenizer(example['text'], truncation=True, max_length=max_lenth, padding="longest")
#return tokenizer(example[0], truncation=True, max_length=max_lenth, padding="max_length")
new_new_dataset = shuffled_dataset.map(dataset_tokener, batched=True, remove_columns=["text"])
print('map over')
configuration = GPT2Config.from_pretrained(hf_model_path, output_hidden_states=False)
model = AutoModelForCausalLM.from_pretrained(hf_model_path)
model.resize_token_embeddings(len(tokenizer))
seed_val = 42
random.seed(seed_val)
np.random.seed(seed_val)
torch.manual_seed(seed_val)
torch.cuda.manual_seed_all(seed_val)
from transformers import Trainer,TrainingArguments
import os
print("strat train")
training_args = TrainingArguments(output_dir="./test_trainer",
num_train_epochs=1.0,
report_to="none",
do_train=True,
dataloader_num_workers=dataloader_num,
local_rank=int(os.environ.get('LOCAL_RANK', -1)),
overwrite_output_dir=True,
logging_strategy='steps',
logging_first_step=True,
logging_dir="./logs",
log_on_each_node=False,
per_device_train_batch_size=batch_size_node,
warmup_ratio=0.03,
save_steps=save_step,
save_total_limit=5,
gradient_accumulation_steps=gradient_accumulation,
max_steps=max_step,
disable_tqdm=False,
data_seed=42
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=new_new_dataset,
eval_dataset=None,
tokenizer=tokenizer,
# Data collator will default to DataCollatorWithPadding, so we change it.
data_collator=DataCollatorForLanguageModeling(tokenizer,mlm=False),
#compute_metrics=compute_metrics if training_args.do_eval and not is_torch_tpu_available() else None,
#preprocess_logits_for_metrics=preprocess_logits_for_metrics
#if training_args.do_eval and not is_torch_tpu_available()
#else None,
)
trainer.train(resume_from_checkpoint=True)
### Expected behavior
use the train code uppper
my dataset ./gpt_data_v1 have 1000 files, each file size is 120mb
start cmd is : python -m torch.distributed.launch --nproc_per_node=8 my_train.py
here is result:
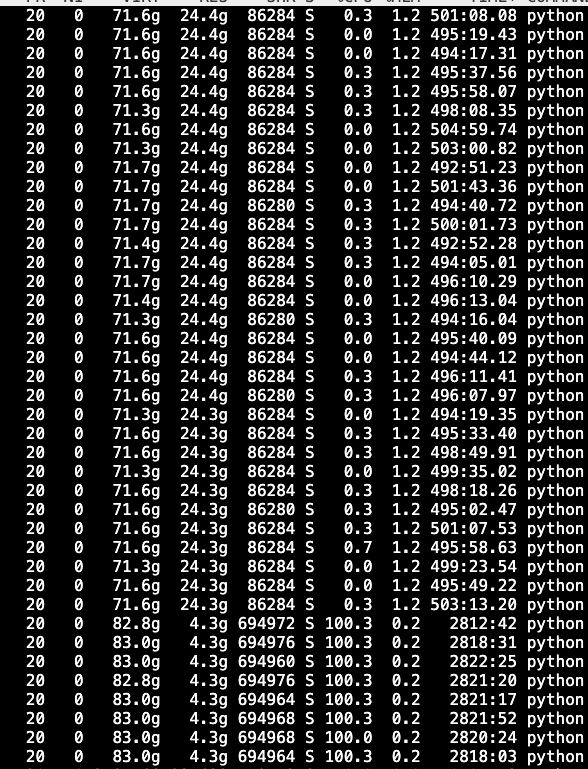
here is memory usage monitor in 12 hours

every dataloader work allocate over 24gb cpu memory
according to memory usage monitor in 12 hours,sometime small memory releases, but total memory usage is increase.
i think datasets streaming mode should not used so much memery,so maybe somewhere has memory leak.