I am a newbie to T5 and transformers in general so apologies in advance for any stupidity or incorrect assumptions on my part!
I am trying to put together an example of fine-tuning the T5 model to use a custom dataset for a custom task. I have the “How to fine-tune a model on summarization” example notebook working but that example uses a pre-configured HF dataset via “load_dataset()” not a custom dataset that I load from disk. So I was wanting to combine that example with the guidance given at “Fine-tuning with custom datasets” but with T5 and not DistilBert as in the fine-tuning example shown.
I think my main problem is knowing how to construct a dataset object that the pre-configured T5 model can consume. So here is my use of the tokenizer and my attempt at formating the tokenized sequencies into datasets:
I have seen the post “Defining a custom dataset for fine-tuning translation” but the solution offered there seems to be write your own custom Dataset loading class rather than directly providing a solution to the problem - I can try to learn/do this but it would be great to get this working equivalent to “Fine-tuning with custom datasets” but for the T5 model I want to use.
I also found “Fine Tuning Transformer for Summary Generation” which is where I got the idea to change the getitem method of my ToxicDataset class to return “input_ids” “input_mask” “output_ids” “output_mask” but I am guessing really, I can’t find any documentation of what is needed (sorry!).
Any help or pointers to find what I need would be very much appreciated!
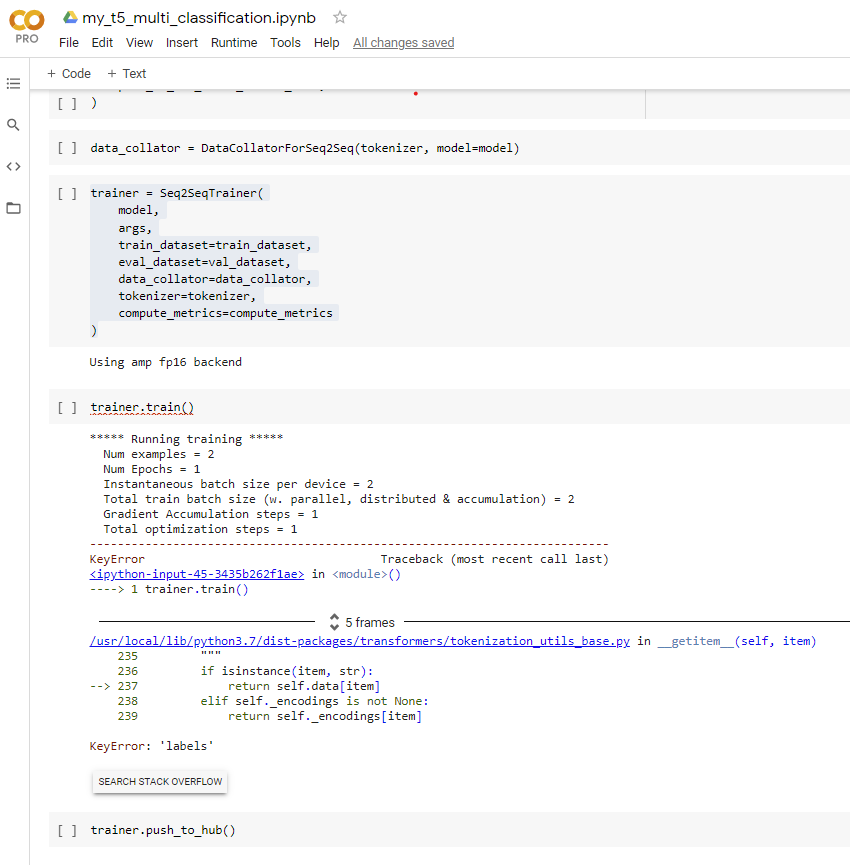
I think I may have found a way around this issue (or at least the trainer starts and completes!). The subclassing of a torch.utils.data.Dataset object for the distilbert example in “Fine-tuning with custom datasets” needs changing as follows. I guess because the distilbert model provides just a list of integers whereas the T5 model has output texts and I assume the DataCollatorForSeq2Seq() takes care of preprocessing the labels (the output encodings) into the features needed by forward function of T5 model (I am guessing, but this is what I am assuming from what I have read). Code changes below:
Clone the transformers repo and I used transformers/examples/pytorch/summarization/run_summarization.py. It is not limited to summarization with T5, just configure the input/output text to what you need.
Hey! Can you pls share the notebook or code snippet that helped you finally train the custom dataset with T5. I’ve been struggling with the same problem. Please help!
It would be great if you you could share how you create dataset, loader and finally train it.
Hi @sheoran95, well I did this about a year back (so there might be something better/different now, please check out other options too) but as I said in my post above, the example code I got running was run_summarization.py from transformers/examples/pytorch/summarization at main · huggingface/transformers (github.com). Take a look at the README.md for how to get started with a example dataset. You want the T5ForConditionalGeneration model and note you need to provide the --source_prefix "summarize: " parameter (which you can later change to other T5 supported prefixes to do other things).
Thanks for such a fast response!
Sure, I’ll check this out.
I actually tried the code changes you mentioned previously and it got my Trainer working.
I was facing an error: “ValueError: You have to specify either decoder_input_ids or decoder_inputs_embeds” but after using AutoModelForSeq2SeqLM instead of AutoModel, it was also resolved.
Is there any specific reason why you shifted to the run_summarization.py file if your Trainer was working?
I switched to that file because the trainer displayed on the hugging face website was out of date and didn’t work, and the Hugging Face folks said that run_summarization.py was working as it is maintained as part of the Transformers repository. Hope that provides some explanation.