Thanks, good point. I was following along the course when I ran into a memory error when running on sagemaker and was trying to debug locally, but then I got sidetracked with other errors. I’ve included the full code that uses the DLC etc.
It gives me the following error:
RuntimeError: CUDA out of memory. Tried to allocate 512.00 MiB (GPU 0; 15.78 GiB total capacity; 14.68 GiB already allocated; 130.75 MiB free; 14.74 GiB reserved in total by PyTorch)
Below is my training script, as well as the notebook that sends the job to sagemaker. I was hoping to jump straight in and use the API, but I may have put the cart before the horse  I’ll continue to debug this on my own and will review all the course material. In the meantime, if you see something obvious that is causing this issue please do let me know. I was told at first that it had to do with batch sizes, but I tried several settings without any luck.
I’ll continue to debug this on my own and will review all the course material. In the meantime, if you see something obvious that is causing this issue please do let me know. I was told at first that it had to do with batch sizes, but I tried several settings without any luck.
I think my main issue is related to the loss but not sure if that ties in to the memory issue. Are there any examples of the train script for a feature extraction/embedding model I can look at? Or if there is a specific part of the course that deals with this specifically.
From the evaluation section of the fine tuning section:
The function must take an EvalPrediction object (which is a named tuple with a predictions field and a label_ids field)
So how do I handle this for an unsupervised learning task? This would affect other TrainingArguments like evaluation_strategy, load_best_model_at_end, metric_for_best_model etc. It’s difficult to figure out the right arguments when I’m also dealing with the cuda memory error, any pointers are much appreciated. The examples seem mainly geared toward supervised learning, and I was hoping for an error message that would indicate what needs to changed about the loss (since my train.py compute_loss uses labels when there are none). The memory error seems to indicate that there is no GPU memory, and checking the instance metrics it looks like the GPU is not used:
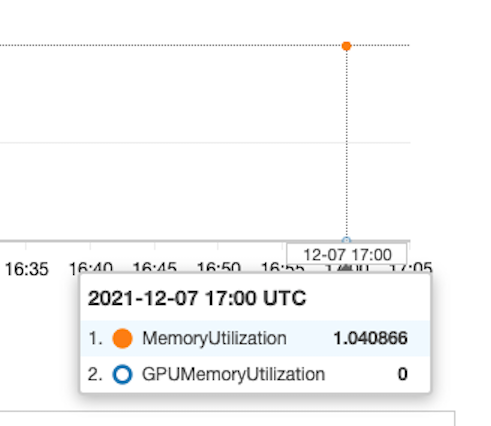
Not sure why that would be as num_gpus is set to 1 in SM_TRAINING_ENV:
Again will continue on with the documentation and course material until I get this sorted out, but any help is appreciated 
train.py
from transformers import (
AutoModel,
Trainer,
TrainingArguments,
AutoTokenizer,
default_data_collator,
)
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
from datasets import load_dataset
import random
import logging
import sys
import argparse
import os
import torch
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# hyperparameters sent by the client are passed as command-line arguments to the script.
parser.add_argument("--epochs", type=int, default=3)
parser.add_argument("--train_batch_size", type=int, default=32)
parser.add_argument("--eval_batch_size", type=int, default=64)
parser.add_argument("--warmup_steps", type=int, default=500)
parser.add_argument("--model_id", type=str)
parser.add_argument("--learning_rate", type=str, default=5e-5)
parser.add_argument("--train_file", type=str, default="train_text.json")
parser.add_argument("--test_file", type=str, default="test_text.json")
parser.add_argument("--fp16", type=bool, default=True)
# Data, model, and output directories
parser.add_argument("--output_data_dir", type=str, default=os.environ["SM_OUTPUT_DATA_DIR"])
parser.add_argument("--model_dir", type=str, default=os.environ["SM_MODEL_DIR"])
parser.add_argument("--n_gpus", type=str, default=os.environ["SM_NUM_GPUS"])
parser.add_argument("--training_dir", type=str, default=os.environ["SM_CHANNEL_TRAIN"])
parser.add_argument("--test_dir", type=str, default=os.environ["SM_CHANNEL_TEST"])
args, _ = parser.parse_known_args()
# Set up logging
logger = logging.getLogger(__name__)
logging.basicConfig(
level=logging.getLevelName("INFO"),
handlers=[logging.StreamHandler(sys.stdout)],
format="%(asctime)s - %(name)s - %(levelname)s - %(message)s",
)
print('\nWalk:')
for path, subdirs, files in os.walk('/opt/ml'):
for name in files: print(os.path.join(path, name))
# load datasets
raw_train_dataset = load_dataset("json", data_files=os.path.join(args.training_dir, args.train_file))["train"]
raw_test_dataset = load_dataset("json", data_files=os.path.join(args.test_dir, args.test_file))["train"]
# load tokenizer
tokenizer = AutoTokenizer.from_pretrained(args.model_id)
# preprocess function, tokenizes text
def preprocess_function(examples):
return tokenizer(examples["inputs"], padding="max_length", truncation=True)
# preprocess dataset
train_dataset = raw_train_dataset.map(
preprocess_function,
batched=True,
)
test_dataset = raw_test_dataset.map(
preprocess_function,
batched=True,
)
# print size
logger.info(f" loaded train_dataset length is: {len(train_dataset)}")
logger.info(f" loaded test_dataset length is: {len(test_dataset)}")
# compute metrics function for binary classification
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
precision, recall, f1, _ = precision_recall_fscore_support(labels, preds, average="micro")
acc = accuracy_score(labels, preds)
return {"accuracy": acc, "f1": f1, "precision": precision, "recall": recall}
print('\nargs.model_id', args.model_id)
# download model from model hub
model = AutoModel.from_pretrained(args.model_id)
# define training args
training_args = TrainingArguments(
output_dir=args.model_dir,
num_train_epochs=args.epochs,
per_device_train_batch_size=args.train_batch_size,
per_device_eval_batch_size=args.eval_batch_size,
warmup_steps=args.warmup_steps,
fp16=args.fp16,
evaluation_strategy="epoch",
save_strategy="epoch",
logging_dir=f"{args.output_data_dir}/logs",
learning_rate=float(args.learning_rate),
load_best_model_at_end=True,
metric_for_best_model="f1",
)
# create Trainer instance
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
tokenizer=tokenizer,
data_collator=default_data_collator,
)
# train model
trainer.train()
# evaluate model
eval_result = trainer.evaluate(eval_dataset=test_dataset)
# writes eval result to file which can be accessed later in s3 ouput
with open(os.path.join(args.output_data_dir, "eval_results.txt"), "w") as writer:
print(f"***** Eval results *****")
for key, value in sorted(eval_result.items()):
writer.write(f"{key} = {value}\n")
# Saves the model to s3
trainer.save_model(args.model_dir)
.
.
.
.
.
Execution notebook
!pip install "sagemaker>=2.48.0"
import sagemaker
sess = sagemaker.Session()
# sagemaker session bucket -> used for uploading data, models and logs
# sagemaker will automatically create this bucket if it not exists
sagemaker_session_bucket=None
if sagemaker_session_bucket is None and sess is not None:
# set to default bucket if a bucket name is not given
sagemaker_session_bucket = sess.default_bucket()
role = sagemaker.get_execution_role()
sess = sagemaker.Session(default_bucket=sagemaker_session_bucket)
print(f"sagemaker role arn: {role}")
print(f"sagemaker bucket: {sess.default_bucket()}")
print(f"sagemaker session region: {sess.boto_region_name}")
# Download some training data
!wget https://github.com/saurabh3949/Text-Classification-Datasets/raw/master/dbpedia_csv.tar.gz
!tar -xzvf dbpedia_csv.tar.gz
import pandas as pd
import json
import os
# Write small train and test files
df = pd.read_csv('dbpedia_csv/train.csv', header = None)
# write as small train input file
with open('train_text.json', 'w') as outfile:
for desc in df.iloc[:10000, 2]:
json.dump({"inputs": desc}, outfile)
outfile.write('\n')
with open('test_text.json', 'w') as outfile:
for desc in df.iloc[10000:15000, 2]:
json.dump({"inputs": desc}, outfile)
outfile.write('\n')
from sagemaker.s3 import S3Uploader
s3_prefix = 'batch-data'
training_input_path = f's3://{sess.default_bucket()}/{s3_prefix}/train'
test_input_path = f's3://{sess.default_bucket()}/{s3_prefix}/test'
# upload datasets
train_remote = S3Uploader.upload('train_text.json',training_input_path)
test_remote = S3Uploader.upload('test_text.json',test_input_path)
print(f"train dataset uploaded to: \n{train_remote}\n{test_remote}")
from sagemaker.huggingface import HuggingFace
import time
mid = 'facebook/bart-large-mnli'
# hyperparameters, which are passed into the training job
hyperparameters={'epochs': 1, # number of training epochs
'train_batch_size': 32, # batch size for training
'eval_batch_size': 64, # batch size for evaluation
'learning_rate': 3e-5, # learning rate used during training
'model_id':mid, # pre-trained model
'fp16': True, # Whether to use 16-bit (mixed) precision training
'train_file': 'train_text.json', # training dataset
'test_file': 'test_text.json', # test dataset
}
metric_definitions=[
{'Name': 'eval_loss', 'Regex': "'eval_loss': ([0-9]+(.|e\-)[0-9]+),?"},
{'Name': 'eval_accuracy', 'Regex': "'eval_accuracy': ([0-9]+(.|e\-)[0-9]+),?"},
{'Name': 'eval_f1', 'Regex': "'eval_f1': ([0-9]+(.|e\-)[0-9]+),?"},
{'Name': 'eval_precision', 'Regex': "'eval_precision': ([0-9]+(.|e\-)[0-9]+),?"}]
# define Training Job Name
job_name = f'hf--{mid.replace("/", "-")}--{time.strftime("%H-%M-%S", time.localtime())}'
instance = 'ml.p3.2xlarge'
# create the Estimator
huggingface_estimator = HuggingFace(
entry_point = 'train.py', # fine-tuning script used in training jon
source_dir = 'scripts', # directory where fine-tuning script is stored
instance_type = instance, # instances type used for the training job
instance_count = 1, # the number of instances used for training
base_job_name = job_name, # the name of the training job
role = role, # Iam role used in training job to access AWS ressources, e.g. S3
transformers_version = '4.6', # the transformers version used in the training job
pytorch_version = '1.7', # the pytorch_version version used in the training job
py_version = 'py36', # the python version used in the training job
hyperparameters = hyperparameters, # the hyperparameter used for running the training job
metric_definitions = metric_definitions # the metrics regex definitions to extract logs
)
# define a data input dictonary with our uploaded s3 uris
training_data = {
'train': train_remote,
'test': test_remote
}
# starting the train job with our uploaded datasets as input
huggingface_estimator.fit(training_data, wait=False)



