Hi @plamb.
I have the same objective as you: classification of multi-page image documents (for example, PDF documents whose pages can be converted to images) by using - at the same time - both the layout and text.
@nielsr of HuggingFace works on Document Image Classification (see his github) but I did not find in this work a notebook/script that classifies from all the document pages.
- DiT (paper):
- performing inference with DiT for document image classification
- performing inference with DiT for document image classification
- LayoutLM (paper):
- fine-tuning
LayoutLMForSequenceClassificationon the RVL-CDIP dataset
- fine-tuning
- LayoutLMv2 (paper):
- fine-tuning
LayoutLMv2ForSequenceClassificationon RVL-CDIP
- fine-tuning
About using LayoutLMv2 for one page document classification, there is also the publication of Karndeep Singh that looks similar to the one of @nielsr
- video “Image Document Classification using LayoutLM”
- notebook: Fine_tuning_LayoutLMv2ForSequenceClassification_on_RVL_CDIP_(using_LayoutLMv2Processor).ipynb
I searched as well in arxiv.org about whole document classification and I found this paper “Towards a Multi-modal, Multi-task Learning based Pre-training Framework for Document Representation Learning” which was updated in January 2022 (see image below). Unfortunately, I did not find any associated code/notebook.
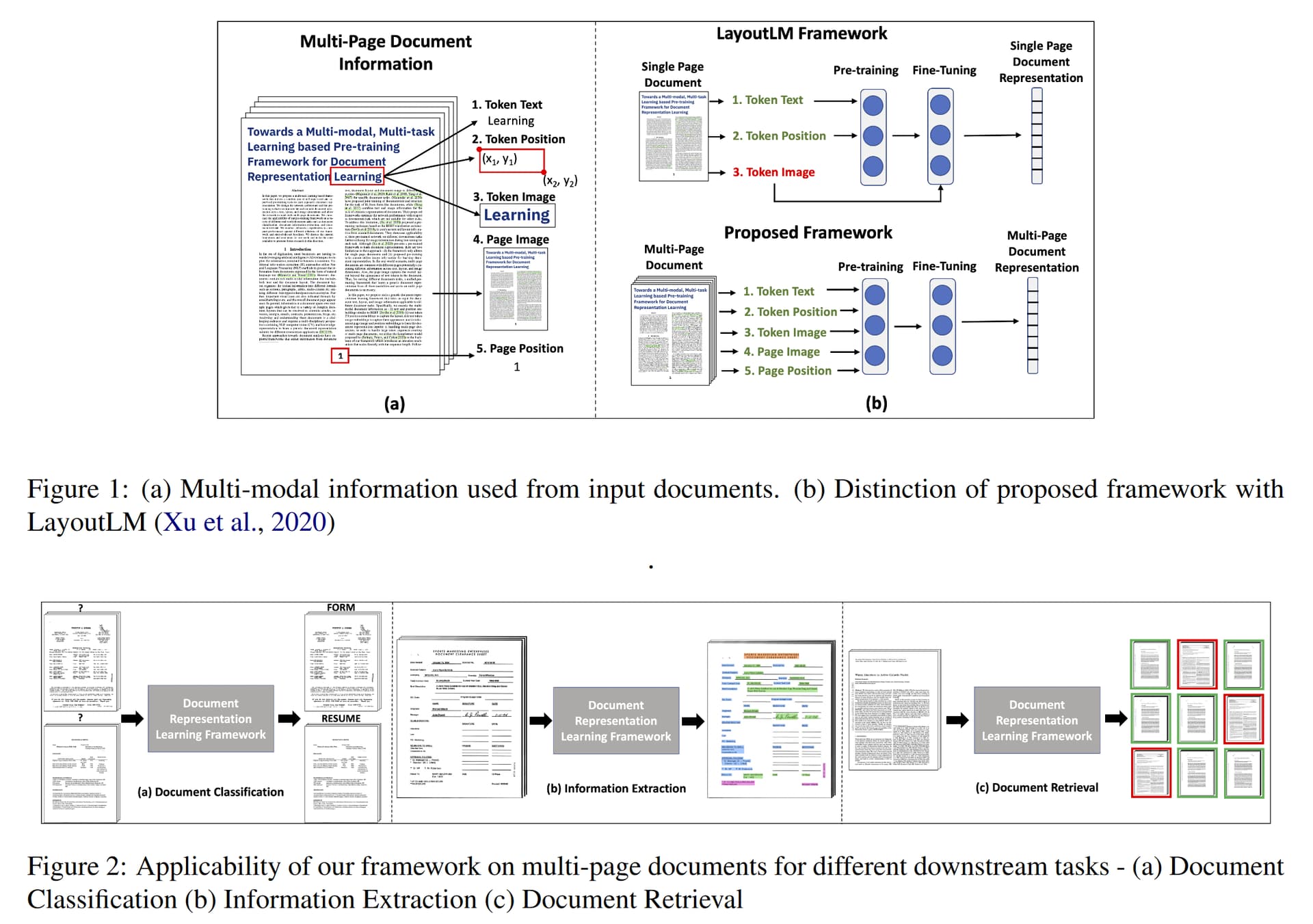
Back to LayoutLMv2 (or LayoutLMv3 now), how do you think we could use it for a multi-page document classification? @nielsr, have you already worked on thus subject? Thanks.