I want use transformers to do text classification, I want code myself rather than use TFBertForSequenceClassification ,so I write the model with TFBertModel and tf.keras.layers.Dense ,but this is no gradient descent in my code, I try to find what wrong with my code but I can’t. So I submit this issues to ask for some help.
my code is here:
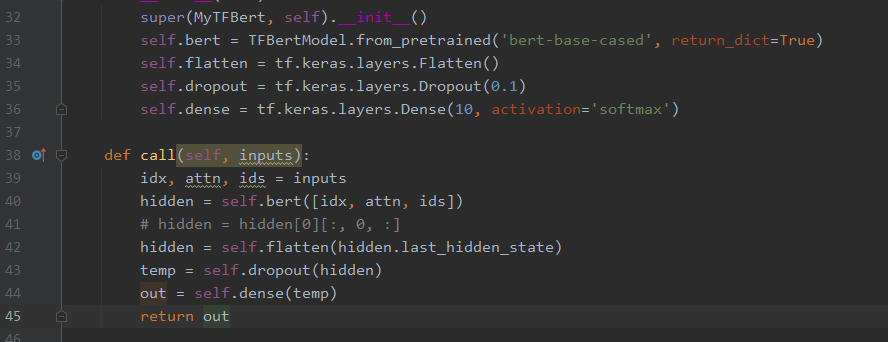
Model:
and I know train data is test data,just for quick debug.
and when I train this model ,
I have seen the document of them for a hold afternoon.You mean the souce code of TFBertForSequenceClassification? But I’m too weak to find the souce code because there are a lot of call…How can I find the souce code.
Thank you very much!!! I will read the source code tommorrow because is too late.Thanks again for your patient !!
But I still can’t understand why the gradient descent was zero.
I see the document last_hidden_state (tf.Tensor of shape (batch_size, sequence_length, hidden_size)) – Sequence of hidden-states at the output of the last layer of the model.
It is the parameters of bert after all,why Dense(FC) can’t match them and do the gradient descent?