I want to find out what model can fit in our GPU. How can I find this info from hugging face model site? For example when I go into llama3 8b model I see the files size is over 200GB (multiple files). If I deploy this model with vllm in Kubernetee, does it mean it will require a persistent volume of over 200GB? Will also need NVRAM of that size too? It is not clear to me how to identify nvram need for each model from hugging face
1 Like
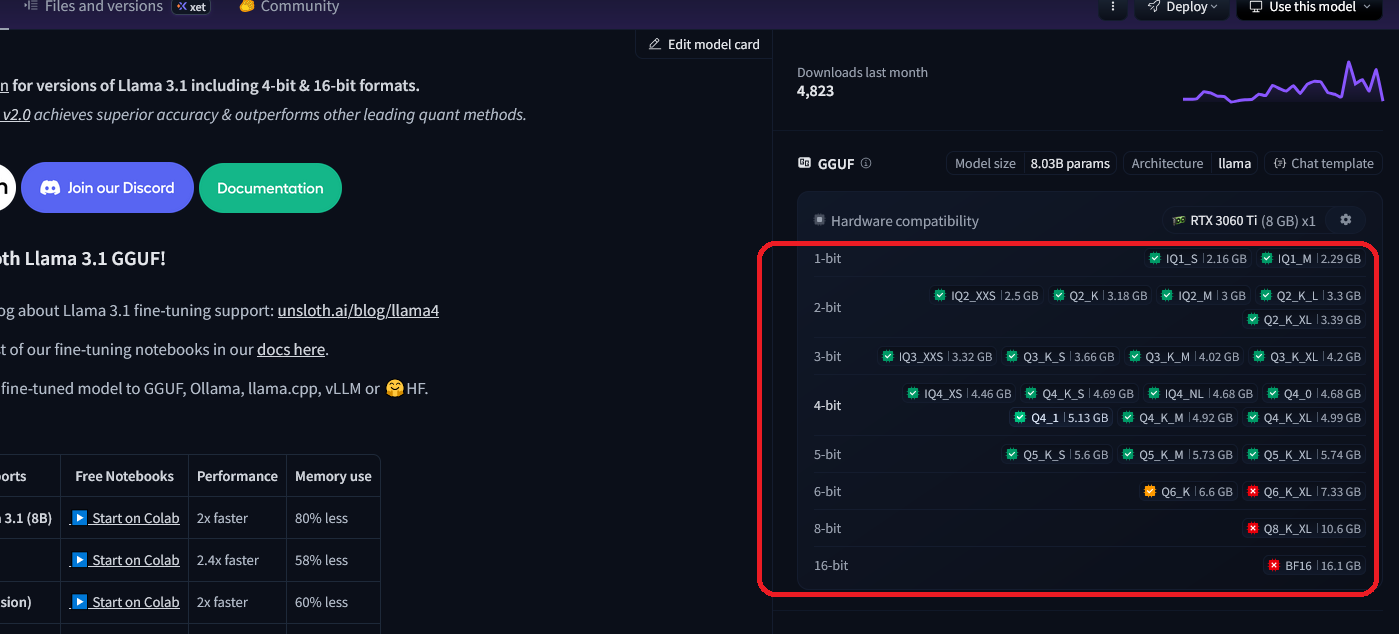
In a conventional LLM architecture, when quantizing to 4 bits, if the model parameter size is 8B, it can run smoothly with 8GB of VRAM, which serves as a general guideline. In this case, the model size itself is smaller than 8GB, but additional memory is required for storing context and other data during inference. If quantization is not applied, it is advisable to estimate 4 to 8 times the VRAM. This is easy to remember.
Additionally, in formats like GGUF, the ability to run on the GPU set in your profile is now displayed as shown in this image. If it’s green, there’s no issue.