Hi, I find an interesting problem in beam_search. In short, the sequential order by beam_search is determined by avg of logits( let’s say length is the same for all candidates). However, the larger avg of logits won’t guarantee the larger avg probability. I am not sure if it is correct.

Code to reproduce:
# %%
from transformers import BartTokenizer,BartForConditionalGeneration
model_path = "/data/pretrained_model/bart_base"
toker = BartTokenizer.from_pretrained(model_path)
model = BartForConditionalGeneration.from_pretrained(model_path)
# %%
input_tokens = ["what do you think it ? huggingface is a great library. And I enjoy it very much",
"transformers is so good"]
batch_size = 2
num_beams = 10
max_length = 5
num_return_sequences = 5
# %%
input_ids = toker(input_tokens,return_tensors='pt',padding=True).input_ids
output = model.generate(input_ids,max_length=max_length,num_beams=num_beams,num_return_sequences=num_return_sequences,
return_dict_in_generate=True,output_scores=True)
# %%
def get_logits_and_probs(output,num_return_sequence,batch_size,eos_token_id):
"""
using for-loop to get positional-wise logits and probability
"""
import torch
total = num_return_sequence * batch_size
token_logits = [[] for _ in range(total)]
token_probs = [[] for _ in range(total)]
continue_or_not = [True for _ in range(total)]
for time_step in range(len(output.scores)):
cur_scores = output.scores[time_step] ## num_beam,vocab_size
for idx in range(total):
cur_beam = output.beam_indices[idx][time_step]
cur_token = output.sequences[idx][time_step+1] ## decoder_start_token_id
if continue_or_not[idx]:
token_probs[idx].append(torch.softmax(cur_scores[cur_beam],dim=-1)[cur_token].item())
token_logits[idx].append(cur_scores[cur_beam][cur_token].item())
if cur_token==eos_token_id:
continue_or_not[idx]=False
return token_logits,token_probs
token_logits,token_probs = get_logits_and_probs(output,num_return_sequences,batch_size,toker.eos_token_id)
# %%
def avg(ls):
return sum(ls)/len(ls)
## check if my get_logits_and_probs function is correct by compare it with output.sequences_scores
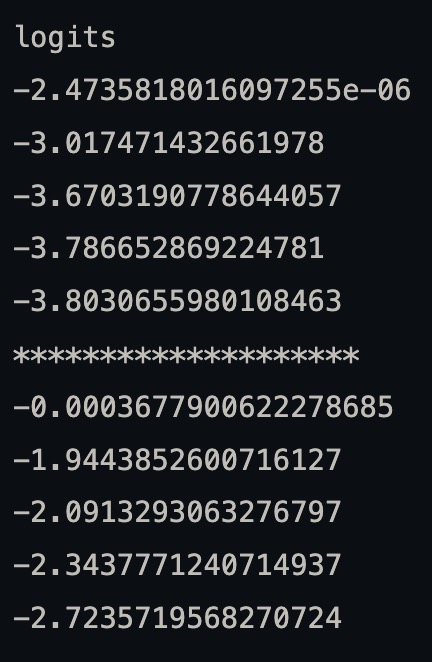
for idx in range(num_return_sequences*batch_size):
if idx == num_return_sequences:
print("*"*20)
print(avg(token_logits[idx]),output.sequences_scores[idx].item())
print("probability")
for idx in range(num_return_sequences*batch_size):
if idx == num_return_sequences:
print("*"*20)
print(avg(token_probs[idx]))