Hello, I am trying to make some code with pyannote/speaker-diarization-3.1 but I got some error that I cannot handle now….
This is the code I made below, I only used function “speaker_diarization” this time..
import pandas as pd
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from pyannote.audio import Pipeline
from pathlib import Path
import os, sys
ffmpeg_dll_dir = Path(r"C:\Users\majh0\miniconda3\Library\bin")
assert ffmpeg_dll_dir.exists(), ffmpeg_dll_dir
os.add_dll_directory(str(ffmpeg_dll_dir))
import torch, torchcodec, platform, subprocess
print("exe:", sys.executable)
print("torch", torch.__version__, "torchcodec", torchcodec.__version__, "py", platform.python_version())
subprocess.run(["ffmpeg", "-version"], check=True)
print("cuda torch?",torch.cuda.is_available())
def whisper_stt(
audio_file_path: str,
output_file_path: str = "./output.csv",
):
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "openai/whisper-large-v3-turbo"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
torch_dtype=torch_dtype,
device=device,
return_timestamps=True,
chunk_length_s=10,
stride_length_s=2,
)
result = pipe(audio_file_path)
df = whisper_to_dataframe(result, output_file_path)
return result, df
def whisper_to_dataframe(result, output_file_path):
start_end_text = []
for chunk in result["chunks"]:
start = chunk["timestamp"][0]
end = chunk["timestamp"][1]
text = chunk["text"]
start_end_text.append([start, end, text])
df = pd.DataFrame(start_end_text, columns=["start", "end", "text"])
df.to_csv(output_file_path, index=False, sep="|")
return df
def speaker_diarization(
audio_file_path: str,
output_rttm_file_path: str,
output_csv_file_path: str,
):
pipeline = Pipeline.from_pretrained(
"pyannote/speaker-diarization-3.1",
token="")
if torch.cuda.is_available():
pipeline.to(torch.device("cuda"))
print("Using CUDA")
else:
print("Using CPU")
print("torch version:", torch.__version__)
print("compiled with cuda:", torch.version.cuda)
print("cuda available:", torch.cuda.is_available())
out = pipeline(audio_file_path)
ann = out.speaker_diarization
# dump the diarization output to disk using RTTM format
with open(output_rttm_file_path, "w", encoding="utf-8") as rttm:
ann.write_rttm(rttm)
df_rttm = pd.read_csv(
output_rttm_file_path,
sep=' ',
header=None,
names=['type', 'file', 'chnl', 'start', 'duration', 'C1', 'C2', 'speaker_id', 'C3', 'C4']
)
df_rttm['end'] = df_rttm['start'] + df_rttm['duration']
df_rttm["number"] = None
df_rttm.at[0, "number"] = 0
for i in range(1, len(df_rttm)):
if df_rttm.at[i, "speaker_id"] != df_rttm.at[i-1, "speaker_id"]:
df_rttm.at[i, "number"] = df_rttm.at[i-1, "number"] + 1
else:
df_rttm.at[i, "number"] = df_rttm.at[i-1, "number"]
df_rttm_grouped = df_rttm.groupby("number").agg(
start=pd.NamedAgg(column="start", aggfunc="min"),
end=pd.NamedAgg(column="end", aggfunc="max"),
speaker_id=pd.NamedAgg(column="speaker_id", aggfunc="first")
)
df_rttm_grouped['duration'] = df_rttm_grouped['end'] - df_rttm_grouped['start']
df_rttm_grouped = df_rttm_grouped.reset_index(drop=True)
df_rttm_grouped.to_csv(output_csv_file_path, sep=',', index=False, encoding='utf-8')
return df_rttm_grouped
if __name__ == "__main__":
# result, df = whisper_stt(
# "./chap05/guitar.wav",
# "./chap05/guitar.csv",
# )
# print(df)
audio_file_path = "./chap05/guitar.wav"
stt_output_file_path = "./chap05/guitar.csv"
rttm_file_path = "./chap05/guitar.rttm"
rttm_csv_file_path = "./chap05/guitar_rttm.csv"
df_rttm = speaker_diarization(
audio_file_path,
rttm_file_path,
rttm_csv_file_path
)
print(df_rttm)
After running this code, it gives me error like below..
(venv) PS C:\GPT_AGENT_2025_BOOK> & C:/GPT_AGENT_2025_BOOK/venv/Scripts/python.exe c:/GPT_AGENT_2025_BOOK/chap05/whisper_stt.py
C:\GPT_AGENT_2025_BOOK\venv\Lib\site-packages\pyannote\audio\core\io.py:47: UserWarning:
torchcodec is not installed correctly so built-in audio decoding will fail. Solutions are:
* use audio preloaded in-memory as a {'waveform': (channel, time) torch.Tensor, 'sample_rate': int} dictionary;
* fix torchcodec installation. Error message was:
Could not load libtorchcodec. Likely causes:
1. FFmpeg is not properly installed in your environment. We support
versions 4, 5, 6 and 7.
2. The PyTorch version (2.9.0+cu126) is not compatible with
this version of TorchCodec. Refer to the version compatibility
table:
https://github.com/pytorch/torchcodec?tab=readme-ov-file#installing-torchcodec.
3. Another runtime dependency; see exceptions below.
The following exceptions were raised as we tried to load libtorchcodec:
[start of libtorchcodec loading traceback]
FFmpeg version 8: Could not load this library: C:\GPT_AGENT_2025_BOOK\venv\Lib\site-packages\torchcodec\libtorchcodec_core8.dll
FFmpeg version 7: Could not load this library: C:\GPT_AGENT_2025_BOOK\venv\Lib\site-packages\torchcodec\libtorchcodec_core7.dll
FFmpeg version 6: Could not load this library: C:\GPT_AGENT_2025_BOOK\venv\Lib\site-packages\torchcodec\libtorchcodec_core6.dll
FFmpeg version 5: Could not load this library: C:\GPT_AGENT_2025_BOOK\venv\Lib\site-packages\torchcodec\libtorchcodec_core5.dll
FFmpeg version 4: Could not load this library: C:\GPT_AGENT_2025_BOOK\venv\Lib\site-packages\torchcodec\libtorchcodec_core4.dll
[end of libtorchcodec loading traceback].
warnings.warn(
exe: C:\GPT_AGENT_2025_BOOK\venv\Scripts\python.exe
torch 2.9.0+cu126 torchcodec 0.8.0 py 3.12.9
ffmpeg version 4.3.1 Copyright (c) 2000-2020 the FFmpeg developers
built with gcc 10.2.1 (GCC) 20200726
configuration: --disable-static --enable-shared --enable-gpl --enable-version3 --enable-sdl2 --enable-fontconfig --enable-gnutls --enable-iconv --enable-libass --enable-libdav1d --enable-libbluray --enable-libfreetype --enable-libmp3lame --enable-libopencore-amrnb --enable-libopencore-amrwb --enable-libopenjpeg --enable-libopus --enable-libshine --enable-libsnappy --enable-libsoxr --enable-libsrt --enable-libtheora --enable-libtwolame --enable-libvpx --enable-libwavpack --enable-libwebp --enable-libx264 --enable-libx265 --enable-libxml2 --enable-libzimg --enable-lzma --enable-zlib --enable-gmp --enable-libvidstab --enable-libvmaf --enable-libvorbis --enable-libvo-amrwbenc --enable-libmysofa --enable-libspeex --enable-libxvid --enable-libaom --enable-libgsm --enable-librav1e --disable-w32threads --enable-libmfx --enable-ffnvcodec --enable-cuda-llvm --enable-cuvid --enable-d3d11va --enable-nvenc --enable-nvdec --enable-dxva2 --enable-avisynth --enable-libopenmpt --enable-amf
libavutil 56. 51.100 / 56. 51.100
libavcodec 58. 91.100 / 58. 91.100
libavformat 58. 45.100 / 58. 45.100
libavdevice 58. 10.100 / 58. 10.100
libavfilter 7. 85.100 / 7. 85.100
libswscale 5. 7.100 / 5. 7.100
libswresample 3. 7.100 / 3. 7.100
libpostproc 55. 7.100 / 55. 7.100
cuda torch? True
Using CUDA
torch version: 2.9.0+cu126
compiled with cuda: 12.6
cuda available: True
C:\GPT_AGENT_2025_BOOK\venv\Lib\site-packages\torch\backends\cuda\__init__.py:131: UserWarning: Please use the new API settings to control TF32 behavior, such as torch.backends.cudnn.conv.fp32_precision = 'tf32'
or torch.backends.cuda.matmul.fp32_precision = 'ieee'. Old settings, e.g, torch.backends.cuda.matmul.allow_tf32 = True, torch.backends.cudnn.allow_tf32 = True, allowTF32CuDNN() and allowTF32CuBLAS() will be deprecated after Pytorch 2.9. Please see https://pytorch.org/docs/main/notes/cuda.html#tensorfloat-32-tf32-on-ampere-and-later-devices (Triggered internally at C:\actions-runner\_work\pytorch\pytorch\pytorch\aten\src\ATen\Context.cpp:85.)
return torch._C._get_cublas_allow_tf32()
C:\GPT_AGENT_2025_BOOK\venv\Lib\site-packages\pyannote\audio\utils\reproducibility.py:74: ReproducibilityWarning: TensorFloat-32 (TF32) has been disabled as it might lead to reproducibility issues and lower accuracy.
It can be re-enabled by calling
>>> import torch
>>> torch.backends.cuda.matmul.allow_tf32 = True
>>> torch.backends.cudnn.allow_tf32 = True
See https://github.com/pyannote/pyannote-audio/issues/1370 for more details.
warnings.warn(
Traceback (most recent call last):
File "c:\GPT_AGENT_2025_BOOK\chap05\whisper_stt.py", line 156, in <module>
df_rttm = speaker_diarization(
^^^^^^^^^^^^^^^^^^^^
File "c:\GPT_AGENT_2025_BOOK\chap05\whisper_stt.py", line 94, in speaker_diarization
out = pipeline(audio_file_path)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\GPT_AGENT_2025_BOOK\venv\Lib\site-packages\pyannote\audio\core\pipeline.py", line 440, in __call__
track_pipeline_apply(self, file, **kwargs)
File "C:\GPT_AGENT_2025_BOOK\venv\Lib\site-packages\pyannote\audio\telemetry\metrics.py", line 152, in track_pipeline_apply
duration: float = Audio().get_duration(file)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\GPT_AGENT_2025_BOOK\venv\Lib\site-packages\pyannote\audio\core\io.py", line 273, in get_duration
metadata: AudioStreamMetadata = get_audio_metadata(file)
^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\GPT_AGENT_2025_BOOK\venv\Lib\site-packages\pyannote\audio\core\io.py", line 86, in get_audio_metadata
metadata = AudioDecoder(file["audio"]).metadata
^^^^^^^^^^^^
NameError: name 'AudioDecoder' is not defined
It says torchcodec is not installed so auodio decoding will fail.. but strange thing is that it tells me the version of torch codec as below….
C:\GPT_AGENT_2025_BOOK\venv\Lib\site-packages\pyannote\audio\core\io.py:47: UserWarning:
torchcodec is not installed correctly so built-in audio decoding will fail.
(...)
[end of libtorchcodec loading traceback].
warnings.warn(
exe: C:\GPT_AGENT_2025_BOOK\venv\Scripts\python.exe
torch 2.9.0+cu126 torchcodec 0.8.0 py 3.12.9
ffmpeg version 4.3.1 Copyright (c) 2000-2020 the FFmpeg developers
built with gcc 10.2.1 (GCC) 20200726
and more strange thing is that this code actually worked pretty well without any problem in Jupyternote book… and last picture is the result..

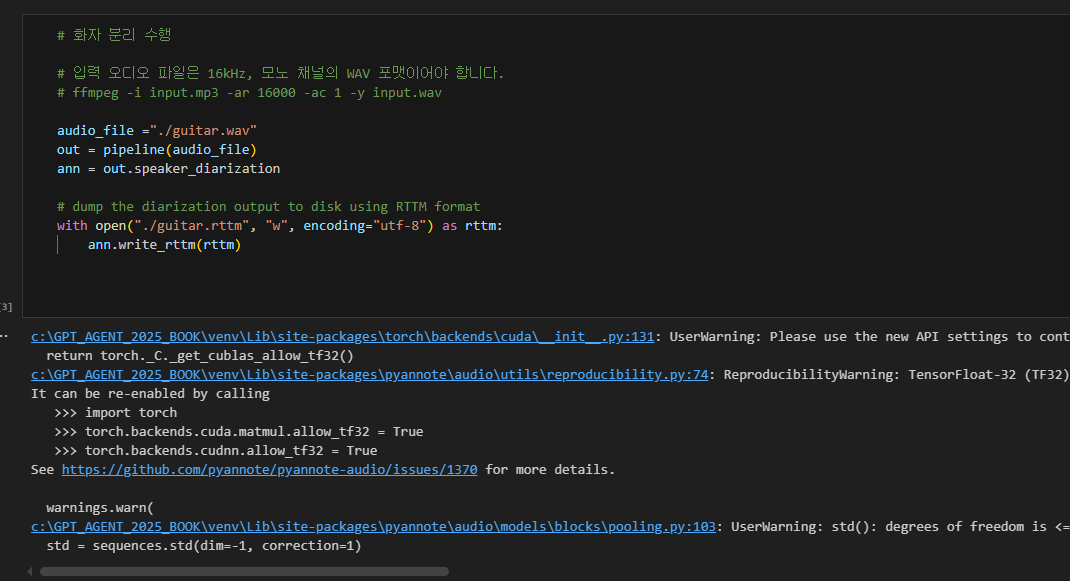
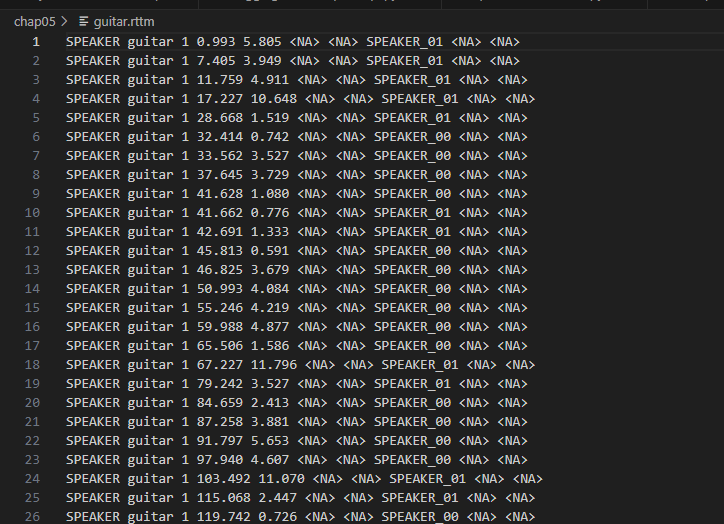
It is hard to understand for me because I didn’t change any environment setting… and I just almost copied and pasted the code from the Jupyternote book..
Thank you so much for the help in advance…