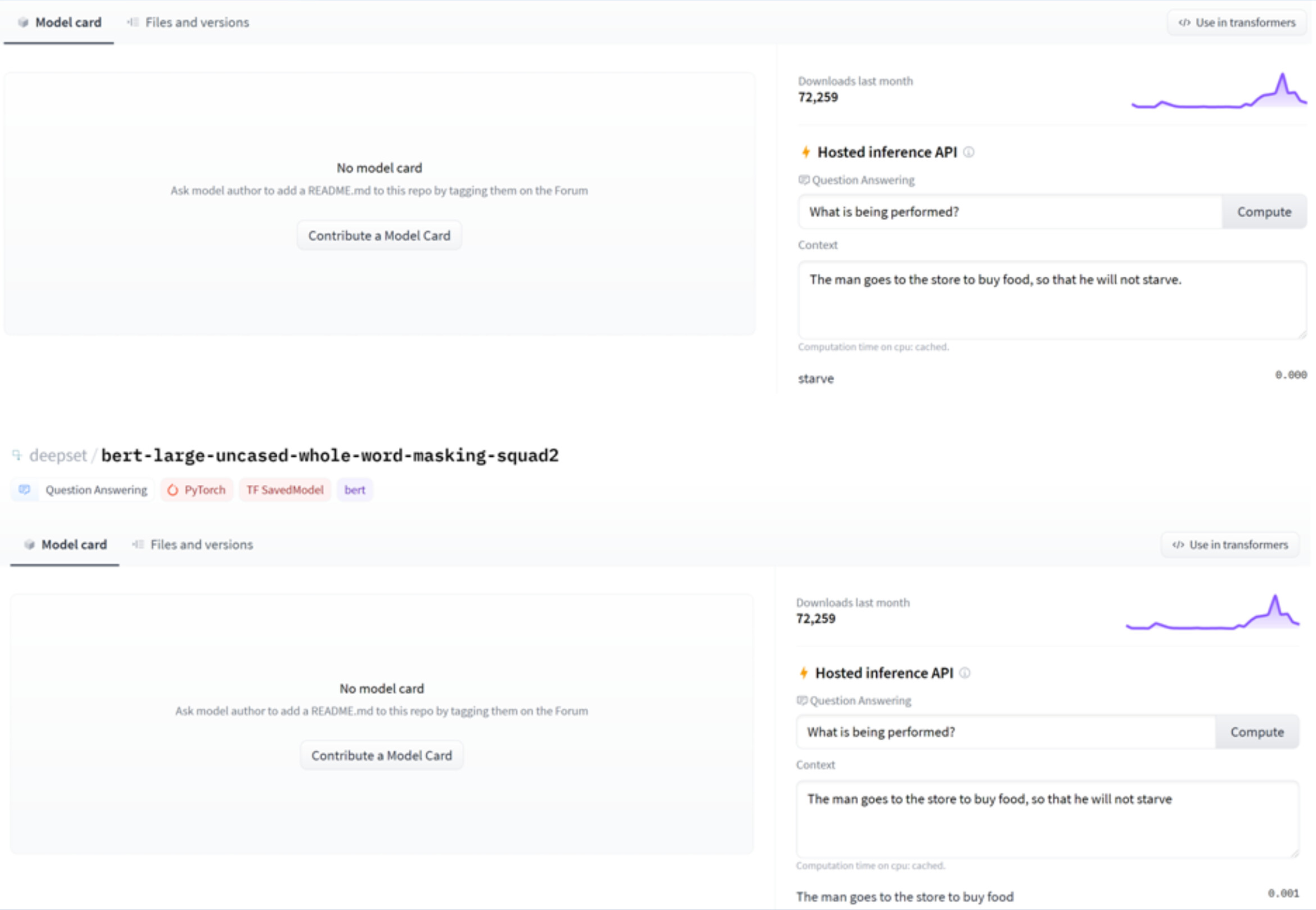
Hi all, I am wondering if anyone might be able to provide some insight or logical reasons for say a BERT model trained on SQuAD for Q & A tasks might output different answers to the same question given the only difference is the absence or presence of a concluding full stop in the context (but also interested in other punctuation/performance for that matter). It does differ between models, the below capture is using
bert-large-uncased-whole-word-masking-squad2 and I get consistent answers from roberta-base-squad2 (that’s obviously not shocking but wanted to add that model robustness might differ between models and why that might be for this particular observation).
Additionally if anyone can recommend any papers on this that would be great!
Hi @pythagorasthe10th, one possible explanation is that BERT’s attention heads are known to pay special attention to commas and full-stops in the last few layers:
Interestingly, we found that a substantial amount of BERT’s attention focuses on a few tokens (see Figure 2). For example, over half of BERT’s attention in layers 6-10 focuses on [SEP]. To put this in
context, since most of our segments are 128 tokens long, the average attention for a token occurring twice in a segments like [SEP] would normally be 1/64. [SEP] and [CLS] are guaranteed to be present and are never masked out, while periods and commas are the most common tokens in the data excluding “the,” which might be why the model treats these tokens differently. A similar pattern occurs for the uncased BERT model, suggesting there is a systematic reason for the attention to special tokens rather than it being an artifact of stochastic training.
I’m not sure if this conclusion carries through to question-answering / fine-tuning, but naively I would guess so. Perhaps you don’t see this in RoBERTa since the next-sentence prediction task is dropped, but I’m not sure about this either.

{kind=link}