Hi, everyone, i am trying to use XLNet for text classification, and i found something different from bert.
my code as
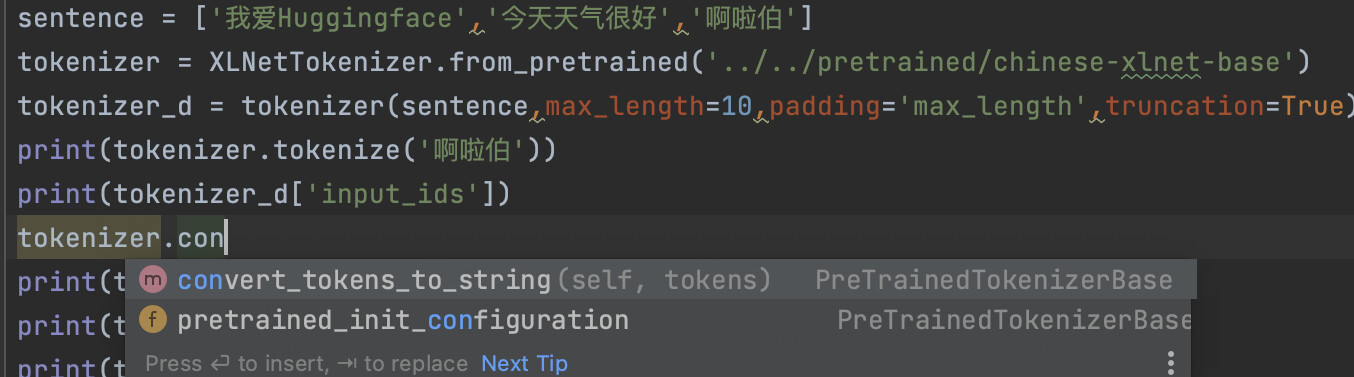
sentence = ['我爱Huggingface','今天天气很好','啊啦伯']
tokenizer = XLNetTokenizer.from_pretrained('../../pretrained/chinese-xlnet-base')
tokenizer_d = tokenizer(sentence,max_length=10,padding='max_length',truncation=True)
print(tokenizer.tokenize('啊啦伯'))
print(tokenizer_d['input_ids'])
my question is : why XLNetTokenizer has no convert_tokens_to_ids method?
transformers version is 4.18.0