I have my model which is the following:-
def create_model(num_encoder_paragraph_tokens,max_encoder_paragraph_seq_length,
num_encoder_question_tokens,max_encoder_question_seq_length,num_decoder_tokens):
hidden_units = 256
embed_hidden_units = 100
context_inputs = Input(shape=(None,), name='context_inputs')
encoded_context = Embedding(input_dim=num_encoder_paragraph_tokens, output_dim=embed_hidden_units,
input_length=max_encoder_paragraph_seq_length,
name='context_embedding')(context_inputs)
encoded_context = Dropout(0.3)(encoded_context)
question_inputs = Input(shape=(None,), name='question_inputs')
encoded_question = Embedding(input_dim=num_encoder_question_tokens, output_dim=embed_hidden_units,
input_length=max_encoder_question_seq_length,
name='question_embedding')(question_inputs)
encoded_question = Dropout(0.3)(encoded_question)
encoded_question = LSTM(units=embed_hidden_units, name='question_lstm')(encoded_question)
encoded_question = RepeatVector(max_encoder_paragraph_seq_length)(encoded_question)
merged = add([encoded_context, encoded_question])
encoder_lstm = LSTM(units=hidden_units, return_state=True, name='encoder_lstm')
encoder_outputs, encoder_state_h, encoder_state_c = encoder_lstm(merged)
encoder_states = [encoder_state_h, encoder_state_c]
decoder_inputs = Input(shape=(None, num_decoder_tokens), name='decoder_inputs')
decoder_lstm = LSTM(units=hidden_units, return_state=True, return_sequences=True, name='decoder_lstm')
decoder_outputs, decoder_state_h, decoder_state_c = decoder_lstm(decoder_inputs,
initial_state=encoder_states)
decoder_dense = Dense(units=num_decoder_tokens, activation='softmax', name='decoder_dense')
decoder_outputs = decoder_dense(decoder_outputs)
model = Model([context_inputs, question_inputs, decoder_inputs], decoder_outputs)
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
encoder_model = Model([context_inputs, question_inputs], encoder_states)
decoder_state_inputs = [Input(shape=(hidden_units,)), Input(shape=(hidden_units,))]
decoder_outputs, state_h, state_c = decoder_lstm(decoder_inputs, initial_state=decoder_state_inputs)
decoder_states = [state_h, state_c]
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = Model([decoder_inputs] + decoder_state_inputs, [decoder_outputs] + decoder_states)
return model, encoder_model, decoder_model

When I train it?
history = model.fit_generator(generator=train_gen, steps_per_epoch=train_num_batches,
epochs=epochs,
verbose=1, validation_data=test_gen, validation_steps=test_num_batches,
callbacks=callbacks)
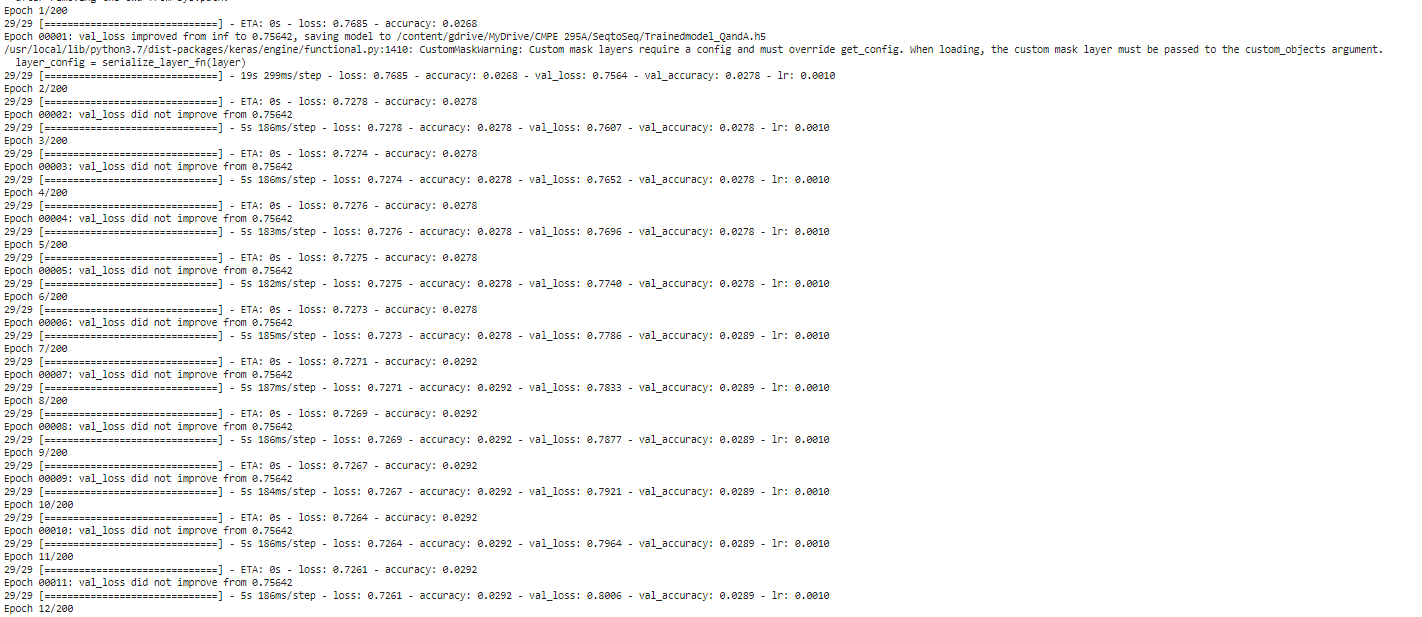

validation loss is not improving, so what is causing the problems?