Hmm…?
1. Direct answer
- Yes, DINOv3 can be used as a backbone for instance and semantic segmentation in general.
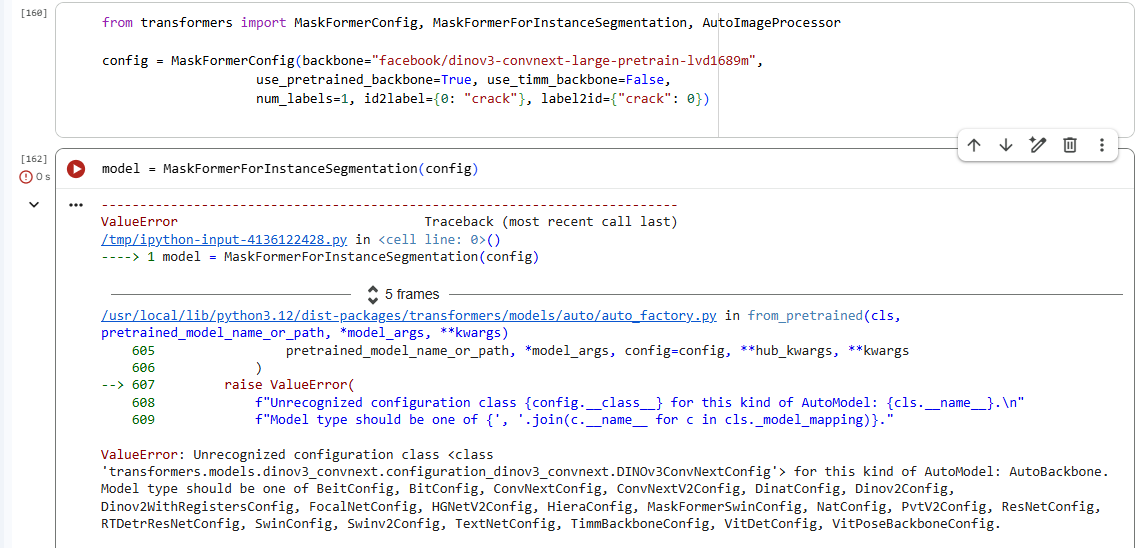
- In Transformers today, there is no “out-of-the-box” MaskFormer/Mask2Former model with a DINOv3 backbone. Your error is essentially saying “this backbone–head combination is not wired up”.
- People have already built DINOv3-based instance and semantic segmentation models, but mostly in custom code or separate repos, not via a single ready-made
MaskFormerForInstanceSegmentation + backbone="facebook/dinov3-..." call.
So: your code is running into a missing integration, not a simple bug.
2. What your current error actually means
You tried something conceptually like:
from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation
config = MaskFormerConfig(
backbone="facebook/dinov3-convnext-large-pretrain-lvd1689m",
use_pretrained_backbone=True,
use_timm_backbone=False,
# ...
)
model = MaskFormerForInstanceSegmentation(config)
Internally this does roughly:
MaskFormerConfig stores backbone="facebook/dinov3-convnext-large-pretrain-lvd1689m".- When the model is built, it calls
AutoBackbone.from_pretrained(backbone_name, ...).
AutoBackbone checks a whitelist of supported backbone config classes (BEiT, BiT, ConvNext, DiNAT, DINOV2, Swin, etc.).(Hugging Face)- Since
facebook/dinov3-convnext-... yields a DINOv3ConvNextConfig, and that config type is not in the accepted list for your version of Transformers, AutoBackbone raises:
ValueError: Unrecognized configuration class DINOv3ConvNextConfig for this kind of AutoModel
That’s exactly what you see: the library doesn’t know how to turn a DINOv3ConvNextConfig into a backbone for MaskFormer in your version.
You are not misusing the API; that combination is simply not wired up.
3. Current status of DINOv3 backbones in Transformers
Transformers now has full DINOv3 model support:
-
DINOv3ViTConfig / DINOv3ViTModel
-
DINOv3ConvNextConfig / DINOv3ConvNextModel
-
And explicitly, backbone classes
Both configs include out_features / out_indices for feature-pyramid style use “when used as backbone”.(Hugging Face)
There are also merged PRs on the transformers repo that add DINOv3 backbones:
- PR #40651 – “Add DINOv3Backbone for ConvNext variant” introduces
DINOv3ConvNextBackbone.(GitHub)
- PR #41276 – “Add dinov3 autobackbone” adds a
DINOv3ViTBackbone and explicitly notes “AutoBackbone integration” with multi-scale feature extraction for detection/segmentation.(GitHub)
So DINOv3 backbones exist and are being integrated into the Backbone API and AutoBackbone on the main branch.
However:
-
The Mask2Former docs explicitly say:
“Currently, Mask2Former only supports the Swin Transformer as backbone.” (Hugging Face)
-
The MaskFormer docs likewise state that MaskFormer currently only supports Swin as backbone, and raise a ValueError if a different backbone type is passed. (Hugging Face)
So even though DINOv3 backbones are there, the MaskFormer/Mask2Former task heads have not yet been generalized to arbitrary backbones in the released code paths. They are still written assuming Swin-style feature maps.
That’s why “DETR with DINOv3 backbone” works (the DETR example tutorial uses the Backbone API with DINOv3ConvNext) but “MaskFormer with DINOv3 backbone” does not.
4. Has anyone actually done DINOv3 + instance segmentation?
Yes, but mostly outside vanilla Transformers:
-
Carti-97/DINOv3-Mask2former on GitHub: description is
“Switch the backbone of mask2former to DINOv3 for instance segmentation.” (GitHub)
This is exactly what you are trying to do, implemented as a custom fork: they patch Mask2Former so it can consume a DINOv3 backbone.
-
Raessan/semantic_segmentation_dinov3:
“Lightweight head for semantic segmentation using DINOv3 as backbone.” (GitHub)
-
WZH0120/DINOv3-UNet:
“Adapting DINOv3 to downstream segmentation tasks.” (GitHub)
-
Raessan/dinov3_ros, sovit-123/dinov3_stack, etc. integrate DINOv3 as backbone for multiple tasks including semantic segmentation, depth, detection. (GitHub)
All of these show that DINOv3 is perfectly usable as a segmentation backbone, but they do it by writing custom heads or custom integrations, not by using MaskFormerForInstanceSegmentation directly.
5. What is and isn’t possible “out of the box” right now
5.1 Instance segmentation with DINOv3 in Transformers
-
Direct, plug-and-play combination
MaskFormerForInstanceSegmentation.from_config(
MaskFormerConfig(backbone="facebook/dinov3-convnext-large-pretrain-lvd1689m", ...)
)
This currently does not work in released code:
- MaskFormer/Mask2Former code still assumes Swin backbones. (Hugging Face)
- AutoBackbone in your installed version doesn’t recognize
DINOv3ConvNextConfig as a valid backbone for MaskFormer, which is exactly your error.
-
If you install Transformers from source on the latest main branch
- DINOv3 backbone classes and AutoBackbone integration exist.(GitHub)
- But MaskFormer/Mask2Former are still documented as Swin-only, so even on
main you should expect to need code changes to the MaskFormer modeling files (or a dedicated MaskFormerDINOv3Config) to avoid shape / channel mismatches.
So: in Transformers proper, instance segmentation with DINOv3 is “possible with modifications”, not officially supported yet.
5.2 Semantic segmentation with DINOv3
Semantic segmentation is somewhat easier, because the head can be simpler:
Many of the DINOv3 repos in the GitHub topic list do exactly this (e.g., semantic_segmentation_dinov3, DINOv3-UNet, dinov3_stack). (GitHub)
So semantic segmentation with DINOv3 is already well-explored in open code, just not as a single prepackaged AutoModelForSemanticSegmentation in Transformers.
6. Practical paths you have right now
Path A – Use a third-party integration for instance segmentation
If your goal is specifically “DINOv3 + Mask2Former instance segmentation”:
-
Study or clone Carti-97/DINOv3-Mask2former.(GitHub)
- They already solved the “how do I feed DINOv3 features into Mask2Former” plumbing.
- You can mirror their architecture and training scripts or adapt them to your dataset.
-
If needed, adapt their repo to:
- Use different DINOv3 checkpoints (
facebook/dinov3-convnext-large-... vs tiny).
- Use your dataset (COCO-style instance masks, etc.).
This is the lowest-friction way to get DINOv3 + instance segmentation today without re-engineering Transformers internals yourself.
Path B – Build your own semantic segmentation head on top of DINOv3Backbone
If you are okay with semantic segmentation (class per pixel) rather than per-instance masks:
-
Instantiate a backbone:
from transformers import DINOv3ConvNextBackbone
backbone = DINOv3ConvNextBackbone.from_pretrained(
"facebook/dinov3-convnext-large-pretrain-lvd1689m",
out_indices=[1, 2, 3], # multiple scales if you want an FPN
)
DINOv3ConvNextBackbone returns BackboneOutput(feature_maps=...), i.e. a tuple of feature maps at different resolutions.(Hugging Face)
-
Write a small decoder in PyTorch:
- Take the deepest feature map, upsample with conv+upsample blocks.
- Optionally fuse lower-level feature maps (FPN-style).
- Final 1×1 conv →
num_classes → bilinear upsample to original image size.
-
Train it:
- Start with the backbone frozen, train only the decoder.
- Optionally unfreeze upper backbone layers and fine-tune with a smaller learning rate.
Functionally, this gives you a DINOv3-based semantic segmentation model using exactly the backbone API that DINOv3 was designed for. You sidestep MaskFormer’s Swin assumptions entirely.
Path C – Use an officially supported segmentation model if DINOv3 is not mandatory
If your priority is “get instance/semantic segmentation working with Transformers and the Backbone API” rather than specifically DINOv3:
You can keep DINOv3 as a feature extractor for other tasks (classification, retrieval) while using Swin / DINOv2 inside segmentation heads that are already officially supported.
7. Summary
Putting it all together: