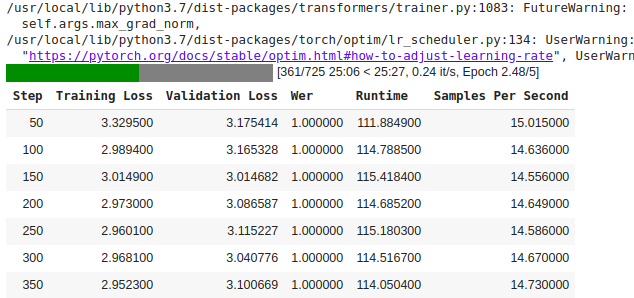
I am also facing the same issue. I am fine-tuning the facebook/wav2vec2-xls-r-300m model over a low-resource language dataset. The WER metric does not change from 1.00 and the predictions are empty strings. I am using transformers==4.24.0 . I have tried setting the parameter do_normalization of Wav2Vec2FeatureExtractor to False, as there was an associated issue on github. However, this didn’t work out.

This is my model:
model = Wav2Vec2ForCTC.from_pretrained(
"facebook/wav2vec2-xls-r-300m",
ctc_loss_reduction="mean",
bos_token_id=processor.tokenizer.bos_token_id,
eos_token_id=processor.tokenizer.eos_token_id,
pad_token_id=processor.tokenizer.pad_token_id,
vocab_size=len(processor.tokenizer),
)
model.freeze_feature_encoder()
These are my training args:
training_args = TrainingArguments(
output_dir=repo_name,
do_train = True,
learning_rate=9.24e-05,
# params for evaluation
do_eval=True,
evaluation_strategy = "epoch",
group_by_length=True,
per_device_train_batch_size=16,
gradient_accumulation_steps=2,
num_train_epochs=30,
gradient_checkpointing=True,
#fp16=True, # available for cuda
save_steps=400,
warmup_steps=500,
save_total_limit=2,
push_to_hub=True,
overwrite_output_dir = True,
# parameter for logs per epochs
logging_strategy="epoch",
logging_dir='./logs',
log_level = "debug",
report_to="wandb",
run_name="quechua-30",
# params for logs per steps
#eval_steps=400,
#logging_steps=400,
)
trainer = Trainer(
model=model,
data_collator=data_collator,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=quechua["train"],
eval_dataset=quechua["dev"],
tokenizer=processor.feature_extractor,
callbacks=[MyCallback]
)
trainer.train()