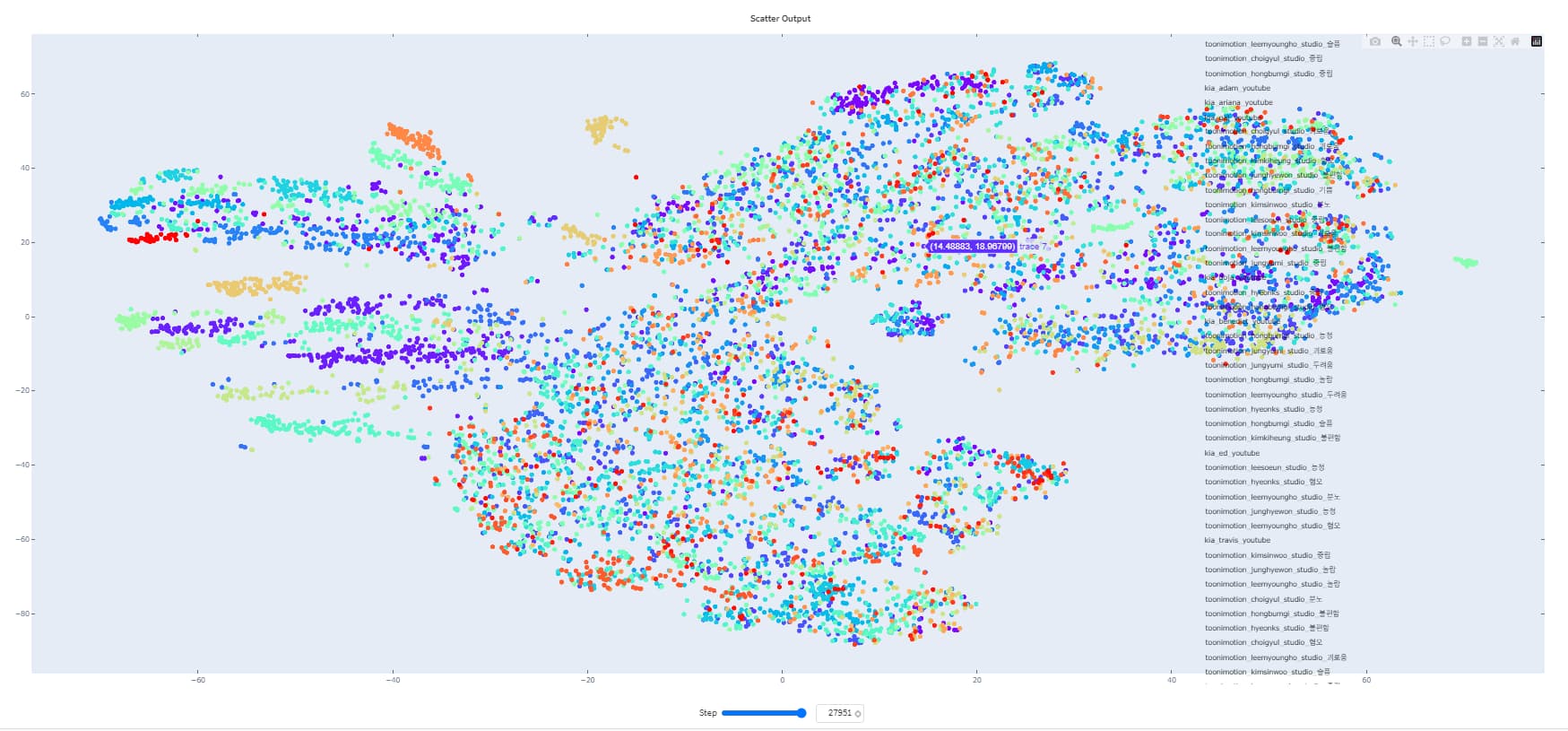
Hello, I’m trying to finetune wav2vec2ForXvector model for speaker verification task.
I used pretrained wav2vec2 base model,
and used only wav2vec2 1th layer for TDNN layer.
Scale of Dataset is 2000k, number of speaker is 11k, batchsize is 256, and learning rate is scheduled by cosine schedule (max 1e-5, min 1e-7)
On this setting, train loss descend too slow until 4th epoch. eer for test set is descending less than I though. And only few classes of embedding vectors are clustered.
In my experience from training ASR, I feel that learning rate and other hyperparameters are important for training progress. Is there a best setting for training TDNN-XVector?
In addition, Does margin or scale setting for additive softmax loss affects strongly for training?