Hey all. Just thought you might be interested in a page I just added to the research docs on the perplexity of fixed-length models.
Perplexity (PPL) is defined as the exponential average of a sequence’s negative log likelihoods. For a t-length sequence X, this is defined,
But with fixed-length models (like most transformers), we can’t always condition on the entire preceding subsequence when predicting each token.
The initial instinct for many in dealing with this problem is to break the whole sequence into segments equal to the model’s max input size and calculate the likelihoods of each segment independently. This not the best approach, however, since it gives the model very little context to use for prediction at the beginning of each segment. I’ll illustrate this with the following gif where we imagine a model with a max input size of 6 adding up the log-likelihoods for the sentence, “Hugging Face is a startup based in New York City and Paris”

When the model starts the second segment, it has to try to predict the word “in” without any context, even though we have 5 words before it that the model could be using (since we said the max input size is 6).
A better approach is to instead employ a sliding window strategy, where you continually move the context across the sequence, allowing the model to take advantage of the available context.
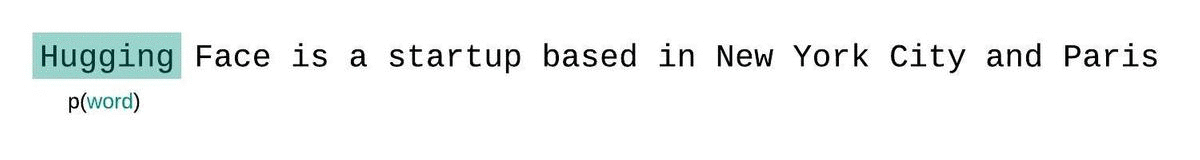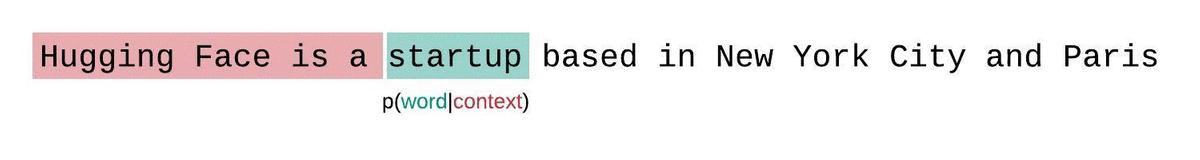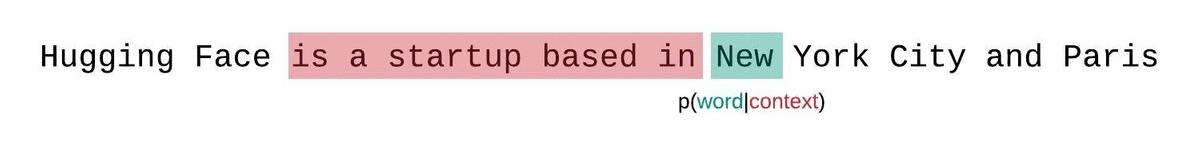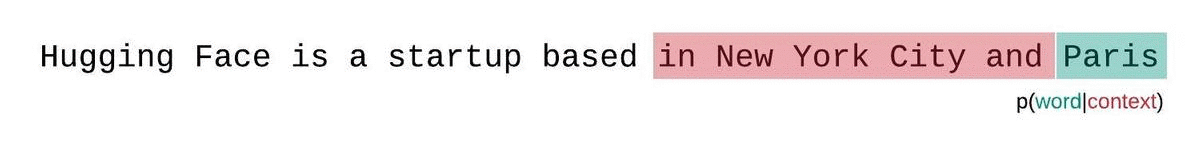
This is slower to compute, but will typically yield better scores and is actually much closer to the way the sequence probabilities are formally decomposed (e.g. see the the equation above).
In the guide, we show how to do this in a strided way with GPT-2. When using the first, naive approach, GPT-2 gets a PPL of 19.64 on WikiText-2. In contrast, when we use a strided sliding window, this score improves dramatically down to 16.53.