In the LLaMA model of the Transformers library, applying rotary embedding seems not correctly implemented, specifically in the rotate_half function (first link). For a query vector [1, 2, 3, 4, 5, 6], the expected output is [-2, 1, -4, 3, -6, 5], but the function returns [-4, -5, -6, 1, 2, 3]. Slicing should have been interleaved. The RoFormer implementation seems correct though (second link).
6 Likes
@reminisce I think you’re correct. I saw the same thing. The embeddings are supposed to be interweaved. In this manner, the embeddings have an identical form at dim 0 that they would at dim x.shape[-1]//2.
(screenshot below shows what I’m referring to in poor detail - it shows dummy data (torch.arange(0, 256).unsqueeze(0).repeat(16, 1) which is why there’s the smooth background color change from 0 to 256) that is encoded with this rotary PE code)
(Note: I haven’t rigorously examined this test, but this simple examination raises my concern that it’s not correct)

Thanks for checking this @GalacticKip7. I actually later found that simply rotating half is also a correct form of rotary embedding (see the following vector-vector multiplication-addition form and the equivalent matrix-vector multiplication form). As long as the matrix (R) satisfies the third equation for any q and k vectors, it’s a valid form of rotary embedding. The only caveat is use the same form for both training and inference.

7 Likes
@reminisce Thank you for the clarification. I’ve only seen the original implementation (see pic) - your pictures help clarify this alternative derivation, though. I’ll try to go over it again once I have a pencil and paper in front of me ![]()

Hi I have the same question after viewing the source code in the huggingface. The key problem here is that we load the original meta llama weights to the huggingface llama model. Thus, the rotary embedding should be designed as the same structure. The source llama meta also use the same rotary embedding (let me know if I am wrong) as original rope paper.
To test if we really need the same setup during training and inference, I change the source code of transformers current main branch to use the original paper. And I get the response of this CodeLlama-7b-hf:
import socket
def ping_exponential_backoff(host: str):
for i in range(1, 10):
try:
# s = socket.socket(socket.AF_INETH, socket.SOCK_STREQ, socket.SOCK_STREUSE_TCP_NODELAY)
s.connect((host, 80))
s.close()
return True
except:
return False
def ping_host(host: str):
for i in range(1, 10):
if ping_host(host):
return True
return False
def ping_host(host: str):
for i in range(1, 10):
if ping_host(host):
return False
def ping_host
If I keep the current transfomers main branch, I can still get meaningful result.
def ping_exponential_backoff(host: str):
"""
Ping a host with exponential backoff.
"""
for i in range(1, 10):
try:
socket.create_connection((host, 80), 5).close()
return True
except OSError as e:
if i < 10:
time.sleep(2 ** i)
else:
raise e
def ping_exponential_backoff_with_timeout(host: str, timeout: int):
"""
Ping a host with exponential backoff and timeout.
"""
for i in range(1, 10):
try:
socket.create_connection((host, 80), timeout).close()
return True
except OSError as e
I guess a more in-depth investigation may be required to compare the comprehensive performance change…
1 Like
Hello, @alexchen4ai
In fact the checkpoint is not totally same.
Please see [LLaMA] Rotary positional embedding differs with official implementation · Issue #25199 · huggingface/transformers · GitHub
They did some weight permutation when convert llama weight to huggingface.
Did you check if it’s really equivalent ? I am having my doubts implementing this in Julia and I would prefer simper concatenation but I am also puzzled by two distinct PyTorch implementations.
I am afraid your answer is not right. Since the \theta is not map correctly. And the key point why transformer’s RoPE only use rotate_half is that in transformers/models/llama/convert_llama_weights_to_hf.py, there exists permute function, which makes the weight rearrange along with last dimension, leading like this:
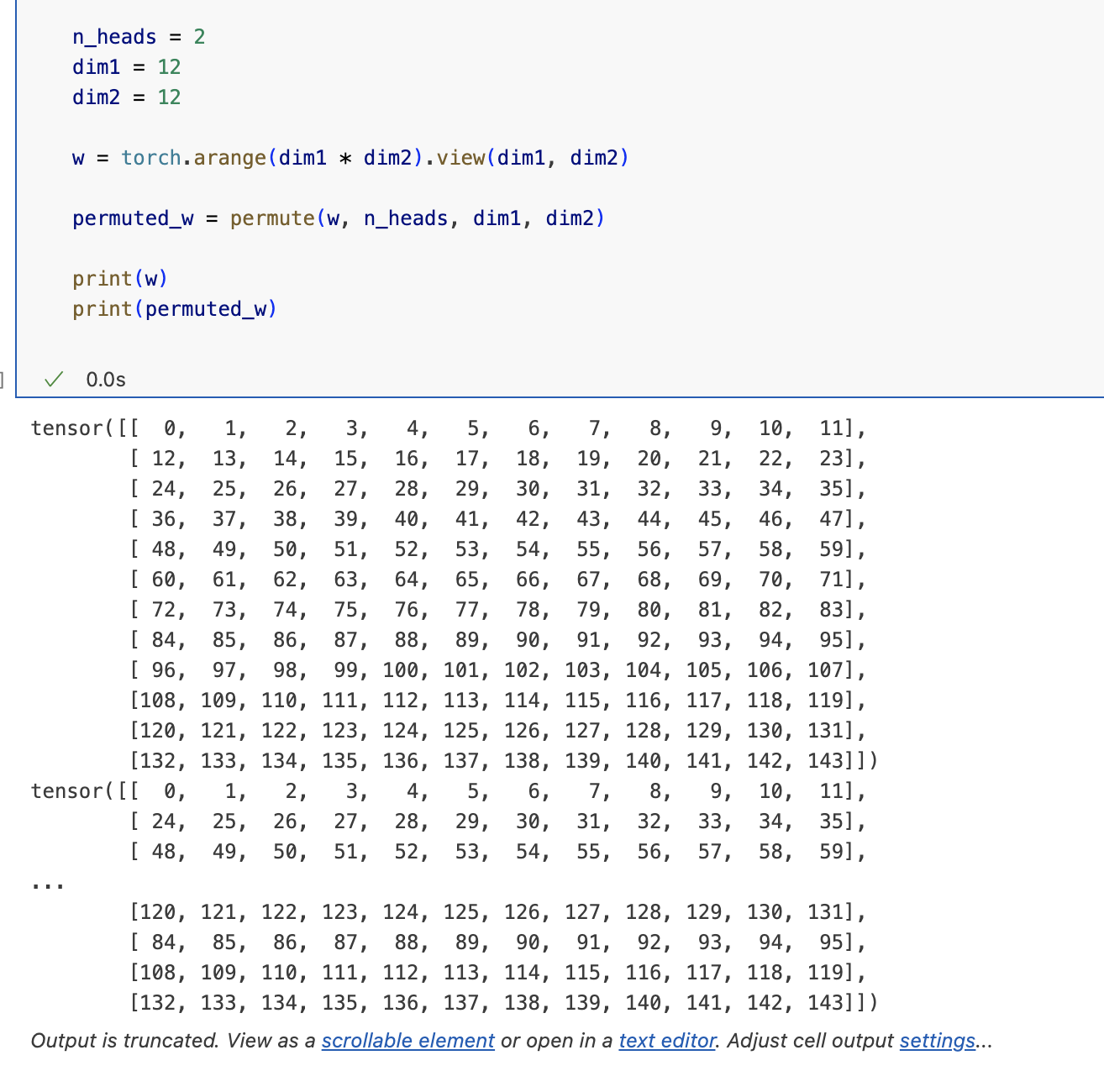
2 Likes