# 🐛 Bug
## Information
The model I am using Bert ('bert-large-uncased') an…d I am facing two issues related to this model
The language I am using the model on English
The problem arises when using:
When I am trying to encode a large sentence ( sentence length 500 words ), I am getting this error :
`IndexError: index out of range in self`
I tried to set max_words length as 400, still getting same error :
Data I am using can be downloaded like this :
```
from sklearn.datasets import fetch_20newsgroups
import re
categories = ['alt.atheism', 'soc.religion.christian','comp.graphics', 'sci.med']
twenty_train = fetch_20newsgroups(subset='train',categories=categories, shuffle=True, random_state=42)
print("\n".join(twenty_train.data[0].split("\n")[:3]))
X_tratado = []
for email in range(0, len(twenty_train.data)):
# Remover caracteres especiais
texto = re.sub(r'\\r\\n', ' ', str(twenty_train.data[email]))
texto = re.sub(r'\W', ' ', texto)
# Remove caracteres simples de uma letra
texto = re.sub(r'\s+[a-zA-Z]\s+', ' ', texto)
texto = re.sub(r'\^[a-zA-Z]\s+', ' ', texto)
# Substitui multiplos espaços por um unico espaço
texto = re.sub(r'\s+', ' ', texto, flags=re.I)
# Remove o 'b' que aparece no começo
texto = re.sub(r'^b\s+', '', texto)
# Converte para minúsculo
texto = texto.lower()
X_tratado.append(texto)
dr = {}
dr ['text'] = X_tratado
dr ['labels'] = twenty_train.target
```
Now I am using bert model to encode the sentences :
```
from transformers import BertModel, BertConfig, BertTokenizer
import torch
tokenizer = BertTokenizer.from_pretrained('bert-large-uncased')
model = BertModel.from_pretrained('bert-large-uncased')
inputs = tokenizer(datar[7], return_tensors="pt")
outputs = model(**inputs)
features = outputs[0][:,0,:].detach().numpy().squeeze()
```
Which is giving this error :
```
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-41-5dcf440b245f> in <module>
5 model = BertModel.from_pretrained('bert-large-uncased')
6 inputs = tokenizer(datar[7], return_tensors="pt")
----> 7 outputs = model(**inputs)
8 features = outputs[0][:,0,:].detach().numpy().squeeze()
~/tfproject/tfenv/lib/python3.7/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
548 result = self._slow_forward(*input, **kwargs)
549 else:
--> 550 result = self.forward(*input, **kwargs)
551 for hook in self._forward_hooks.values():
552 hook_result = hook(self, input, result)
~/tfproject/tfenv/lib/python3.7/site-packages/transformers/modeling_bert.py in forward(self, input_ids, attention_mask, token_type_ids, position_ids, head_mask, inputs_embeds, encoder_hidden_states, encoder_attention_mask, output_attentions, output_hidden_states)
751
752 embedding_output = self.embeddings(
--> 753 input_ids=input_ids, position_ids=position_ids, token_type_ids=token_type_ids, inputs_embeds=inputs_embeds
754 )
755 encoder_outputs = self.encoder(
~/tfproject/tfenv/lib/python3.7/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
548 result = self._slow_forward(*input, **kwargs)
549 else:
--> 550 result = self.forward(*input, **kwargs)
551 for hook in self._forward_hooks.values():
552 hook_result = hook(self, input, result)
~/tfproject/tfenv/lib/python3.7/site-packages/transformers/modeling_bert.py in forward(self, input_ids, token_type_ids, position_ids, inputs_embeds)
177 if inputs_embeds is None:
178 inputs_embeds = self.word_embeddings(input_ids)
--> 179 position_embeddings = self.position_embeddings(position_ids)
180 token_type_embeddings = self.token_type_embeddings(token_type_ids)
181
~/tfproject/tfenv/lib/python3.7/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
548 result = self._slow_forward(*input, **kwargs)
549 else:
--> 550 result = self.forward(*input, **kwargs)
551 for hook in self._forward_hooks.values():
552 hook_result = hook(self, input, result)
~/tfproject/tfenv/lib/python3.7/site-packages/torch/nn/modules/sparse.py in forward(self, input)
112 return F.embedding(
113 input, self.weight, self.padding_idx, self.max_norm,
--> 114 self.norm_type, self.scale_grad_by_freq, self.sparse)
115
116 def extra_repr(self):
~/tfproject/tfenv/lib/python3.7/site-packages/torch/nn/functional.py in embedding(input, weight, padding_idx, max_norm, norm_type, scale_grad_by_freq, sparse)
1722 # remove once script supports set_grad_enabled
1723 _no_grad_embedding_renorm_(weight, input, max_norm, norm_type)
-> 1724 return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
1725
1726
IndexError: index out of range in self
```
The second issue I am facing, When I am using this bert model to encode many sentences, It seems Bert is not using GPU :
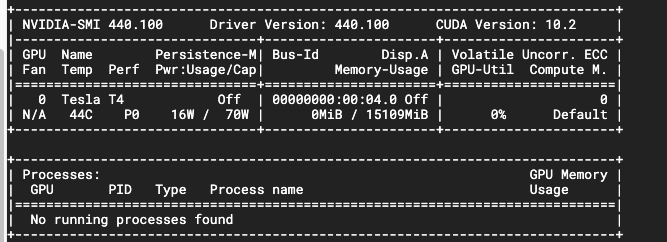
How to accelerate GPU while using bert model?
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: '3.0.0'
- Platform: Ubuntu 18.04.4 LTS
- Python version: python3.7
- PyTorch version (GPU?):
- Tensorflow version (GPU?): '2.2.0
- Using GPU in script?:
- Using distributed or parallel set-up in script?: