I think it’s the design of datasets library. If you explicitly want to convert, you can also use the .to_*** functions.
# deps: pip install datasets pyarrow pandas
# docs:
# - Column return on column-name indexing: https://huggingface.co/docs/datasets/en/access
# - New Column object in releases: https://github.com/huggingface/datasets/releases
# - Access underlying Arrow table: https://discuss.huggingface.co/t/datasets-arrow-help/18880
# - pyarrow.Table.column API: https://arrow.apache.org/docs/python/generated/pyarrow.Table.html
from datasets import Dataset
import pyarrow as pa
def to_conversations(batch):
convs = []
for p, s in zip(batch["problem"], batch["generated_solution"]):
convs.append(
[{"role": "user", "content": p},
{"role": "assistant", "content": s}]
)
return {"conversations": convs}
# --- minimal toy data ---
base = Dataset.from_dict({
"problem": ["P1", "P2", "P3"],
"generated_solution": ["S1", "S2", "S3"],
})
ds = base.map(to_conversations, batched=True)
print("=== REPRO: column-name indexing returns Column ===")
col = ds["conversations"]
print("type(ds['conversations']) =", type(col)) # datasets.arrow_dataset.Column
print("col[0] =", col[0]) # first conversation
assert "datasets.arrow_dataset.Column" in str(type(col)) # expected on modern versions
print("\n=== FIX 1: get Python list when you need it ===")
as_list = list(ds["conversations"]) # materialize as plain list
print("type(list(ds['conversations'])) =", type(as_list))
print("as_list[0] =", as_list[0])
assert isinstance(as_list, list)
print("\n=== FIX 2: get the Arrow column when you need it ===")
arrow_col = ds.data.column("conversations") # pyarrow.ChunkedArray
print("type(ds.data.column('conversations')) =", type(arrow_col))
assert isinstance(arrow_col, pa.ChunkedArray)
print("\n=== Reference: row-first vs column-first access ===")
print("row-first type:", type(ds[0]["conversations"])) # Python object for a single row
print("column-first type:", type(ds["conversations"])) # Column wrapper
"""
=== REPRO: column-name indexing returns Column ===
type(ds['conversations']) = <class 'datasets.arrow_dataset.Column'>
col[0] = [{'content': 'P1', 'role': 'user'}, {'content': 'S1', 'role': 'assistant'}]
=== FIX 1: get Python list when you need it ===
type(list(ds['conversations'])) = <class 'list'>
as_list[0] = [{'content': 'P1', 'role': 'user'}, {'content': 'S1', 'role': 'assistant'}]
=== FIX 2: get the Arrow column when you need it ===
type(ds.data.column('conversations')) = <class 'pyarrow.lib.ChunkedArray'>
=== Reference: row-first vs column-first access ===
row-first type: <class 'list'>
column-first type: <class 'datasets.arrow_dataset.Column'>
"""
I don’t very understand, will it convert to Column on the earth? what determines the type of newly added columns?
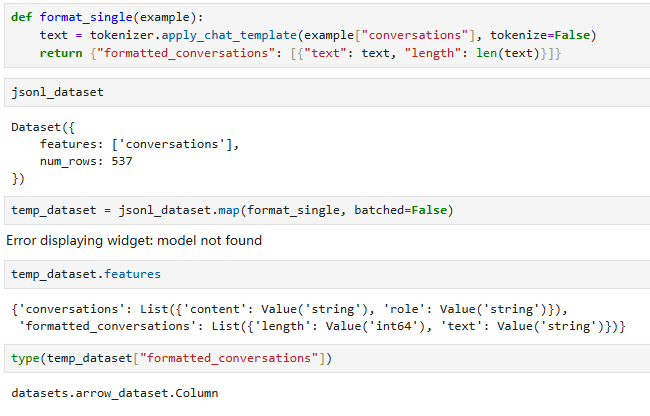
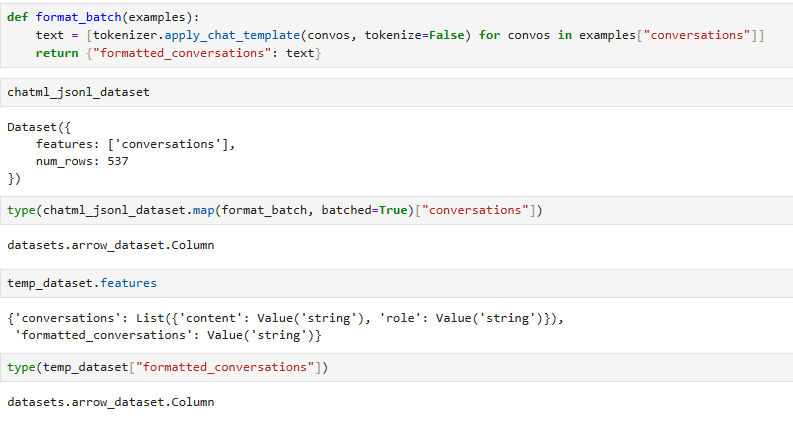
what determines the type of newly added columns?
Basically by added data('s type) itself or Features if specified.
ds["formatted_conversations"] returns a Column view. Nothing is converted; it exposes the Arrow-backed column. Hugging Face documents that column-name indexing returns a Column object you can index like a list. (Hugging Face)
Type of a newly added column is set as follows:
- You specify it. Pass a
Featuresschema when creating or mapping. That schema becomes the column’s Arrow type. You can later change it withcastorcast_column. (Hugging Face) - If you do not specify it, Datasets infers the type from the Python values your
mapreturns. Inference is Arrow-based. (Hugging Face) - Complex returns like
list[dict{...}]become nested features such asSequence({...}). Features define column names and types. (Hugging Face) - The dataset is backed by a PyArrow Table; low-level access is via
ds.data.column("col")which yields aChunkedArray. (Hugging Face)
Minimal patterns:
# control the new column type explicitly
from datasets import Features, Sequence, Value
features = Features({
"formatted_conversations": Sequence({"text": Value("string"), "length": Value("int32")})
})
ds = ds.map(fn, batched=False, features=features) # schema fixed by you
# if already created, change just one column's feature
ds = ds.cast_column("formatted_conversations",
Sequence({"text": Value("string"), "length": Value("int32")})) # cast if compatible
# access choices
col_view = ds["formatted_conversations"] # Column view
arrow_arr = ds.data.column("formatted_conversations") # pyarrow.ChunkedArray
py_list = list(ds["formatted_conversations"]) # plain list
Sources: column access and Column view, features and schema control, casting columns, Arrow backing and column() API. (Hugging Face)
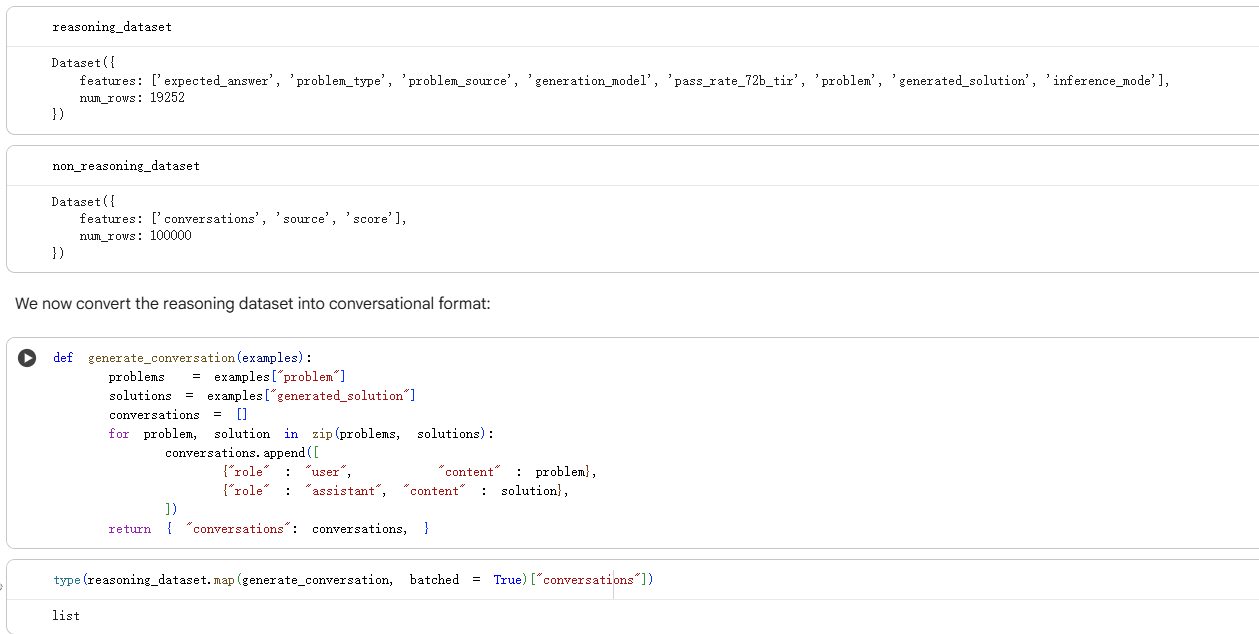
def generate_conversation(examples):
problems = examples["problem"]
solutions = examples["generated_solution"]
conversations = []
for problem, solution in zip(problems, solutions):
conversations.append([
{"role" : "user", "content" : problem},
{"role" : "assistant", "content" : solution},
])
return { "conversations": conversations, }
print(type(reasoning_dataset.map(generate_conversation,batched=True)[conversations ]))
that’s clear, but it did not use features parameter in the code above, why it still got a list instead of Column?
Oh… It seems the behavior depends on the version of the datasets library…
It’s version behavior, not features=.
-
Why you saw a list: older
datasetsreturned a Python list fords["col"]. Newer versions return adatasets.arrow_dataset.Columnview. Thefeatures=argument never controls this accessor; it only sets schema. (Hugging Face) -
What it is now:
ds["col"]→ Column view backed by a PyArrow table. The dataset is Arrow-backed. (Hugging Face) -
What sets the type of new columns:
- Explicit schema you pass via
features=inmapor later viacast_column/cast. - Otherwise Arrow infers from the Python values your function returns. This becomes
dataset.features. (Hugging Face)
- Explicit schema you pass via
-
Make results consistent regardless of version:
import datasets, pyarrow as pa print(datasets.__version__) col_view = ds["conversations"] # Column on new versions, list on old as_list = list(ds["conversations"]) # always a Python list arrow_ca = ds.data.column("conversations") # always a pyarrow.ChunkedArrayThe Arrow interop is stable because the dataset is a PyArrow table underneath. (Hugging Face)
-
Tip for nested data: Returning
list[dict]frommapyields a nestedSequence(struct{...})feature unless you override withfeatures=. Check withds.features. (Hugging Face)
If you need Column everywhere, upgrade datasets; if you need lists, wrap with list(...).
The datasets’s version is “4.0.0”, I use it in unsloth’s official notebook, is that very old?
in myself’s environment the version is 4.2.0
so u mean if the same code was run in myself’s environment, I’ll get a Column?
***
I’ve tried, u r right

wait, I tried it in unsloth’s notebook again and it become Column!
but I really remember that I’ve ever got a list type and the top screenshot can prove
god, maybe there is some halloween ghost who’s trick me
If you want to avoid ambiguity in data types, it’s probably better to explicitly cast them…
It’s too random.![]()