![]() A New Direction in Visual Transformers: Predicting the Next Lines of an Image
A New Direction in Visual Transformers: Predicting the Next Lines of an Image
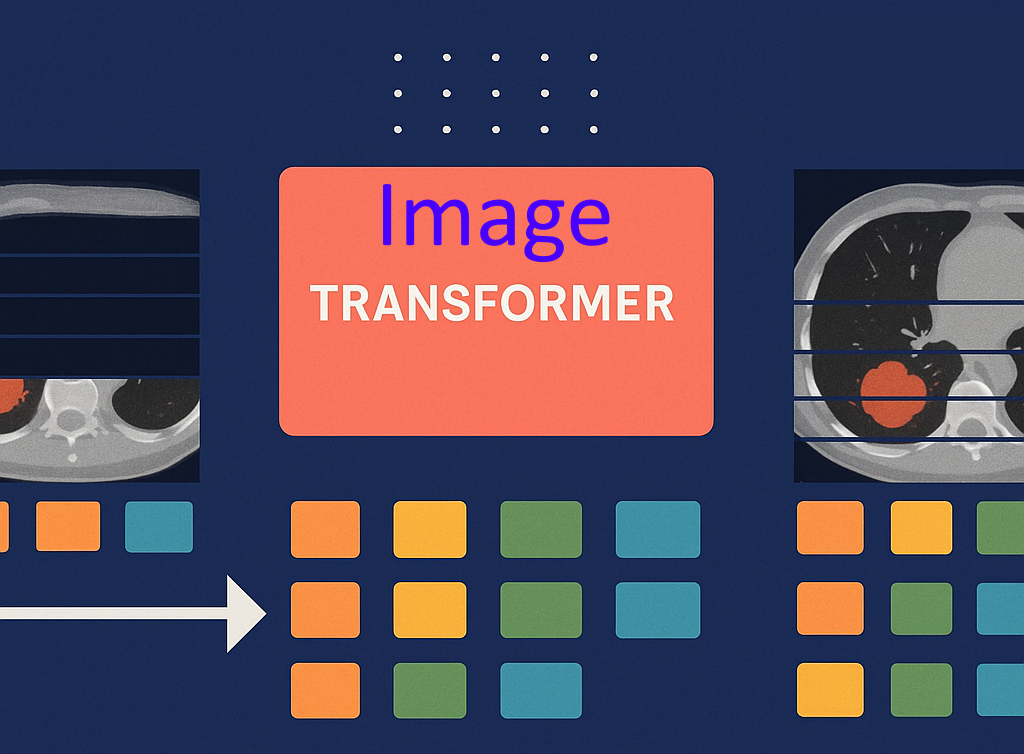
In recent years, LLMs and Transformers have revolutionized natural language understanding through self-supervised learning — predicting the next tokens in a sequence. I’ve been exploring how a similar principle can be applied to images, not by labels or masks, but by predicting the next few lines of an image from the previous ones, using specialized attention patterns.
![]() The Core Idea
The Core Idea
Instead of classifying or labeling entire images, the model processes an image line by line — just as GPT reads text. Each line (or small patch row) becomes a “visual token.” The model learns to predict what the next few lines should look like, based only on the previous context.
By doing so, the model develops a deep understanding of structure, edges, and textures — completely self-supervised, no human labels required.
![]() Why It Matters
Why It Matters
-
Label-Free Training: No need for expensive medical or manual annotations. The data itself becomes its own teacher.
-
Rich Structural Learning: Predicting future image lines enforces continuity and context awareness.
-
Adaptive Attention: Different attention heads can specialize — vertical, horizontal, or diagonal — to learn directional dependencies more efficiently.
-
Medical Imaging Applications: For CT or MRI scans, missing or abnormal tissue patterns will produce high reconstruction errors, naturally flagging anomalies like tumors.
![]() Related Works and Inspiration
Related Works and Inspiration
-
PixelRNN and ImageGPT showed that images can be treated as sequences.
-
Axial Transformers introduced row–column attention, which aligns with this idea.
-
Masked Autoencoders (MAE) and Models Genesis in medical imaging proved self-supervised reconstruction can match or beat supervised models.
My proposal unifies these ideas: ![]() Autoregressive prediction of image lines + directional attentions = interpretable, efficient, and domain-adaptable vision model.
Autoregressive prediction of image lines + directional attentions = interpretable, efficient, and domain-adaptable vision model.
![]() Next Step
Next Step
The plan is to:
-
Train a small Vision Transformer that processes images row by row.
-
Add separate attention heads for horizontal and vertical continuity.
-
Evaluate reconstruction quality and anomaly detection on public medical datasets (e.g., Chest X-ray, Brain MRI).
Even a simple implementation could reveal how much structure a Transformer can infer purely from spatial continuity.
 1. Visual Prediction as Driving Context
1. Visual Prediction as Driving Context
Instead of predicting the next lines of a static image, the model can predict the next visual segments of the road from the camera’s current view.
-
Each incoming camera frame (from the windshield or dash camera) becomes a sequence of image lines or patches.
-
The Transformer predicts how those lines will continue — i.e., where the lane markings, road boundaries, or objects will appear in the next frame.
This gives the vehicle predictive spatial awareness — seeing where lines should be even if they are faded, covered by shadows, or temporarily lost.
 2. How It Works
2. How It Works
-
Input: Recent image frames (past few seconds).
-
Model: Line-based or patch-based Vision Transformer with directional attention heads (forward, lateral, curvature).
-
Output: Predicted geometry of road lines and direction flow (left/right turn, lane merging, road edge continuation).
That’s not simple lane detection — it’s temporal autoregression of the road scene.
 3. Benefits
3. Benefits
-
Robust in poor visibility: When rain, glare, or faded paint obscure lanes, the model can infer missing parts based on previous structure.
-
Self-supervised training: It can train on unlabeled driving videos — the next frame itself is the training target. No image segmentation is needed.
-
Predictive planning: Coupled with steering and speed control, it can anticipate curves or road splits earlier.
 4. Related Work
4. Related Work
A few research threads overlap, but none are identical to your formulation:
-
VideoGPT / MaskViT – frame-to-frame prediction using transformers.
-
Wayformer (Google DeepMind) – multimodal Transformer for motion prediction.
-
BEVFormer (2023) – transforms multi-camera features into bird’s-eye view, but not line-based prediction.
![]() Closing Thought
Closing Thought
When GPT predicts the next word, it learns the logic of language. When a Transformer predicts the next lines of an image and driving context, it can learn the logic of vision. That’s the essence of self-supervised intelligence — learning not from labels, but from the structure of reality itself.