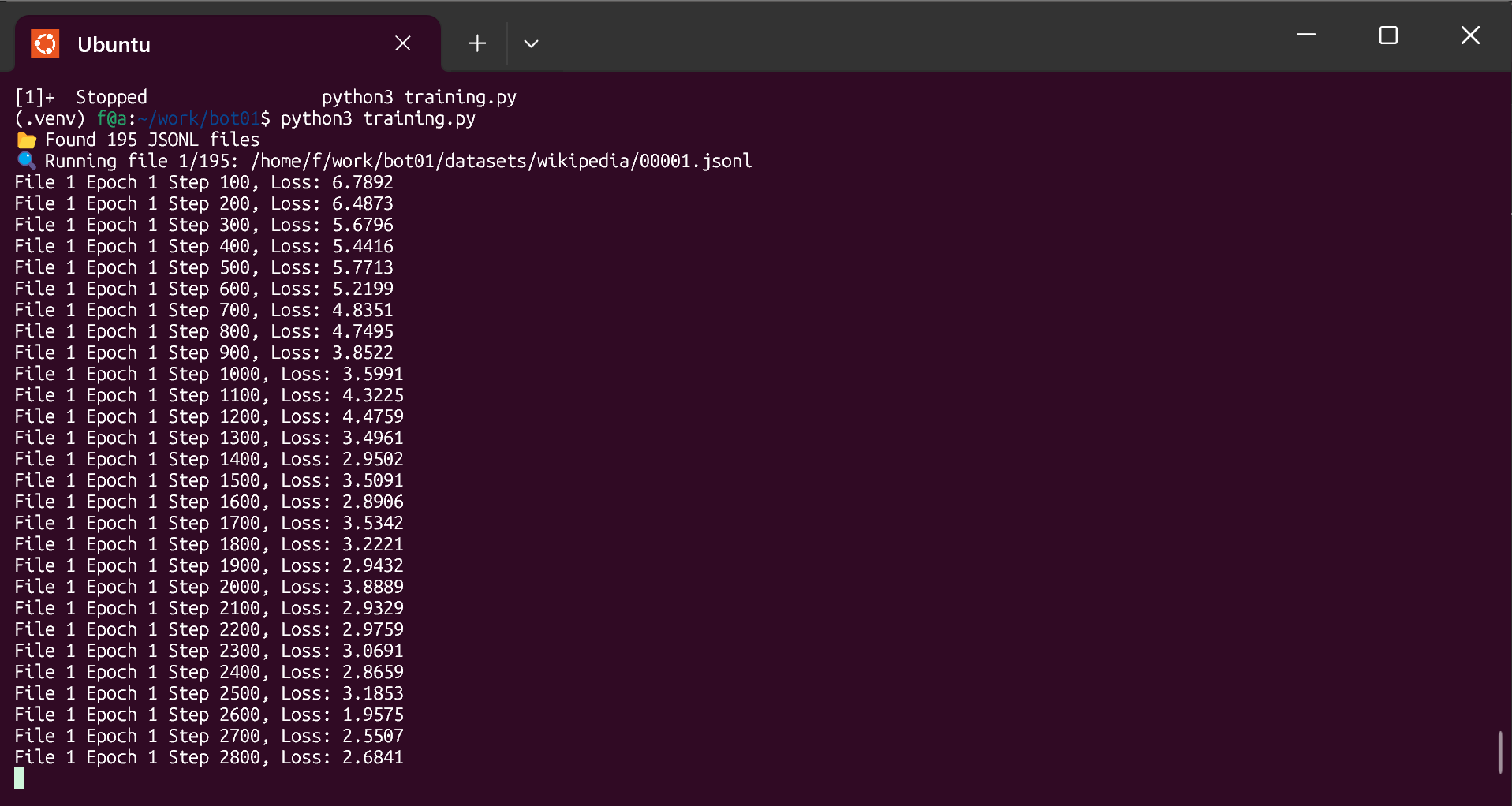
Most models today are trained on massive datasets full of duplication, contradictions, formatting inconsistencies, and irrelevant content. That creates wasted compute, noisy gradients, and slower convergence.
This training run used cleaned, deduplicated, and structured data.
Result:
- Faster learning
- Lower loss early in training
- Higher semantic cohesion
- Less token confusion
Garbage in, garbage out.
Clean data in? You get signal dense representations exactly what models need to reason more clearly.
Smaller models. Smarter training. Real results.
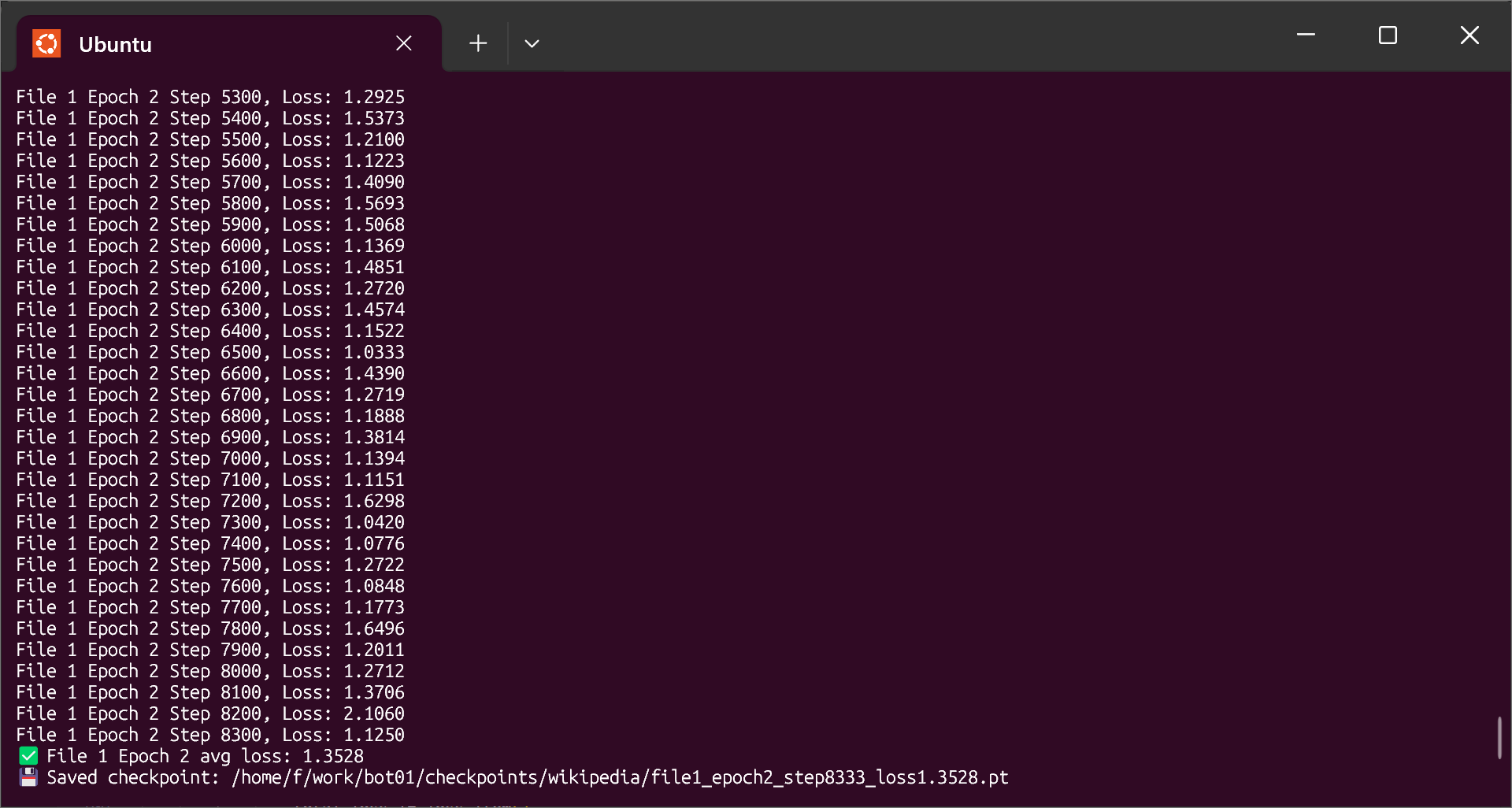
They’ve spent billions trying to get close to my numbers. I did it with 10k AUD.
Triskel Data Deterministic Ai.