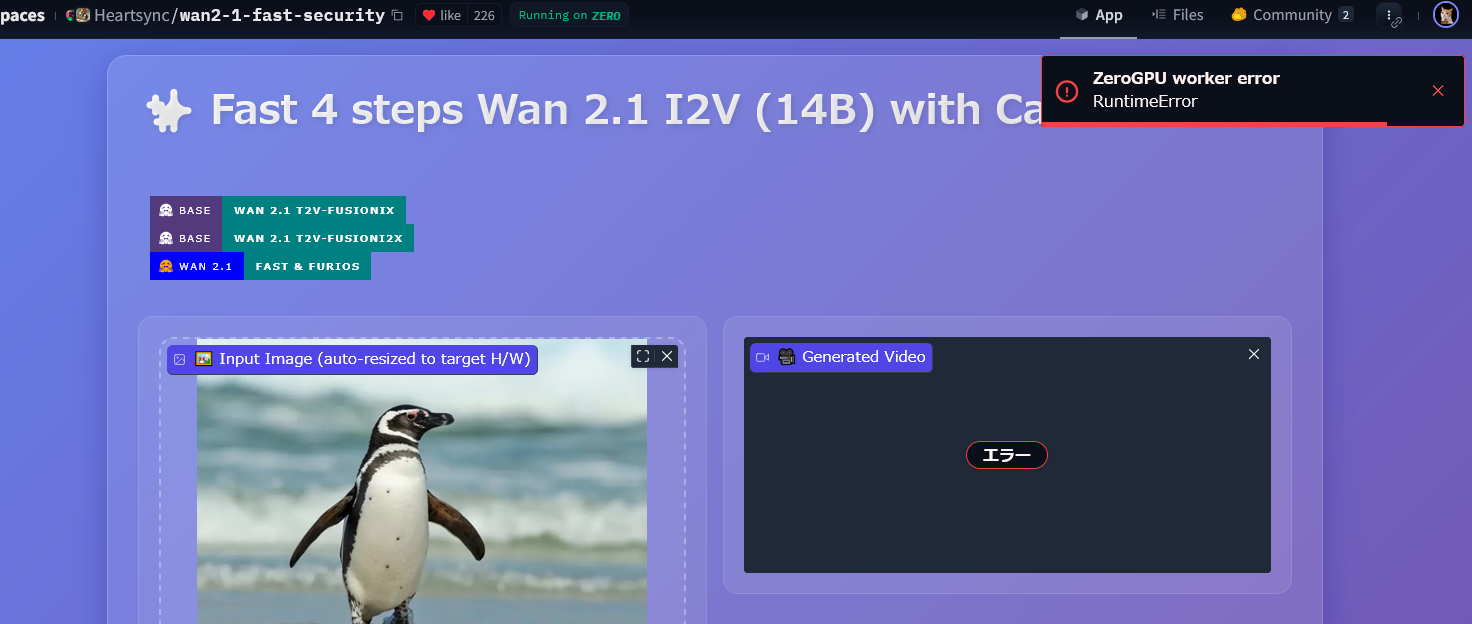
[Did perform a search. The only other thread discussing a similar topic was deleted by the user so here goes.]
For the last few days while using ZeroGPU to generate content, I was getting quite a lot of “ZeroGPU worker error RuntimeError”-s. It was eating up a lot of my daily 25 minutes generation quota, but still, with intermittent retries I could at least finish the generation. However, since today, the Zero GPU Worker Errors have almost become instantanous on clicking the generate button, making it impossible to generate anything at all.
Can anyone tell me if they are/were facing similar issues? And if there is any workaround to the issue?
I have the exact same problem and duplicating the space didn’t work for me.
The problem is not with this space. So far, every zero gpu spaces I’ve tested has had the same problem.
Which Spaces have you tried?
I get the same error in the Spaces mentioned above, but other than that, I can’t reproduce it.
I’ve tried duplicating some ZeroGPU Spaces, but they worked fine.
For example, these Spaces work fine.
Looking at the code, I found a change in Gradio’s specifications.
I can’t believe it, but could Gradio’s repeated specification changes be causing code conflicts…?
Thank you.
Well, maybe the combination of library versions at the time the space was launched was just bad.
Anyway, if it works fine after restarting, it’s probably not a big problem.
The dependency issue still isn’t resolved since we don’t know which library caused the error. Restarting a Space usually doesn’t rebuild it, so restarting fixed the original Space. But when you duplicate it, it triggers a rebuild and the dependencies that aren’t pinned get updated to the latest version. That’s why the Wan 2.2 Space still isn’t working.
Looking at the code, I found a change in Gradio’s specifications.
I can’t believe it, but could Gradio’s repeated specification changes be causing code conflicts…?
Forgot to mention, but there’s a misunderstanding in this comment.
cache_examples still accepts “lazy” in gradio 5.x so that gradio 4.x Spaces that specify cache_examples=”lazy” won’t break when upgrading to gradio 5.x. It shows a warning that it will stop working in the future. You mentioned that we’ve changed it repeatedly, but that’s not the case.
Hello, I’m experiencing the same “runtime error” on Pony Realism, and I don’t really understand how to resolve it. I’ve tried other applications like Image to Video, and after just a few videos, the problem also started to appear. I haven’t been able to generate any images for almost two days. This is starting to cause problems for my current work. Please help me. I need a simple solution that doesn’t require programming.